PFCP の概要
Preferred Computing Platform™(PFCP™)は、Preferred Networks が構築・運用する深層学習・AI ワークロード向けのクラウドサービスです。独自開発したアクセラレータ MN-Core™ シリーズを唯一利用でき、高い AI 計算力と計算効率を実現できます。
強力な計算ボードと高速なネットワーク
MN-Core 2 ボードを 8 基搭載した MN-Server 2 V1 サーバを複数専有して利用できます。 すべてのノードは深層学習に最適化された高速なネットワークで相互に接続されています。

フルマネージドサービス
深層学習・AI ワークロード向けに拡張された Kubernetes クラスタ1をマルチテナントで利用できます。 大規模分散学習から推論サーバの高可用な運用まで幅広く機械学習ワークロードを実行できます。 ワークロードの状況を観測するためのマネージドなモニタリングサービス2も付随しています。
そのほかの特徴
- ユーザの権限管理、ネットワーク ACL の制御が柔軟に行えます
- 高信頼な永続ストレージを使用してデータを保存できます
- 多くの Kubernetes カスタムアドオンが追加されており、AI ワークロードの実行や監視をすぐに始められます
- コマンドラインツールを用いて、PFCP が提供するコンテナイメージを使用して任意のワークロード設定ファイルから実行できます
- ユーザが管理するコンテナイメージを持ち込んでの利用も可能です
- パブリッククラウドとの連携をサポートし、強い権限を持つ鍵を使用せずにパブリッククラウドのリソースを安全に利用できます
-
Kubernetes は、Cloud Native Computing Foundation(CNCF)にホストされたオープンソースのコンテナオーケストレーションプラットフォームです。コンテナ化されたアプリケーションの展開、スケーリング、可用性の管理を自動化するためのツールで、この分野の標準として広く採用されています。 ↩
-
Grafana、Prometheus、Alertmanager といったオープンソースのツールで構成されています。 ↩
用語集
PFCP で使用される用語について説明します。
組織
PFCP を利用する際に必要であり、Kubernetes クラスタの利用、ポータルの利用、認証認可などのベースとなるリソースです。 一般的にテナントと呼称されるものに相当します1。
PFCP を利用するには、利用したい組織から招待される必要があります。 また、Kubernetes クラスタやポータルなどの PFCP リソースを操作するときは、組織の選択が必要です。
1 つの組織で PFCP の複数クラスタが利用可能であり、複数の Namespace を作成できます。 Namespace 単位で権限分離・ネットワーク隔離も可能です。 このため、利用するリージョンごと・利用する用途ごとに、組織を細かく分割する必要はありません。
ルートネームスペース・サブネームスペース
PFCP では、各組織ごとに Namespace が 1 つ提供され、追加の Namespace はその Namespace に従属する Namespace として作成されます。 前者をルートネームスペース、後者をサブネームスペースと呼びます。 PFCP のネームスペースの詳細については、Namespace でクラスタを論理的に分割する をご確認ください。
ルートネームスペースとサブネームスペースは標準の Kubernetes クラスタにはない、PFCP 独自の用語です。 ルートネームスペースとサブネームスペースとでは仕様や扱い方が異なるため、区別する必要がある場合はこれらの呼称を使用しています。 一方で、Kubernetes の Namespace リソース全般にあてはまる記述であり、ルートネームスペースとサブネームスペースのどちらであるかを区別する必要がない場合は、 Namespace を使用しています。
ユーザロール(組織管理者・一般ユーザ)
PFCP には、組織管理者・一般ユーザの 2 種類のロールが定義されています。 ロールの詳細や利用できる操作については、PFCP のロール をご確認ください。
一方、Kubernetes には RBAC2 を実現するために Role/ClusterRole リソースがあります。 PFCP でも標準の ClusterRole3 が提供されていますが、この ClusterRole と PFCP のユーザロールは一対一でマッピングされません4。 組織管理者が RoleBinding を作成することで、Namespace ごとにマッピングを変更できます。
一般ユーザのユーザを個別に対象とする RoleBinding を作成することも、ユーザをグループにまとめ、グループを対象に RoleBinding を作成することも可能です。
RoleBinding の詳細については、 ユーザのクラスタアクセス権限を管理する をご確認ください。 ユーザ管理の詳細については、 組織のユーザを管理する をご確認ください。
モニタリングサービス
PFCP でマネージドサービスとして提供している、Grafana、Prometheus、Alertmanager の総称です。
Identity-Aware Proxy(IAP)
PFCP で提供している、ワークロードをインターネットに公開するための仕組みです。 アクセス時の認証が自動で設定されるため、ワークロードを安全に公開できます。
認証方式の違いにより API Identity-Aware Proxy(API IAP)と WebApp Identity-Aware Proxy(WebApp IAP)の 2 つに分かれています。 詳細な使い方は ワークロードをウェブ API として公開する または ワークロードをウェブアプリとして公開する を参照してください。
-
Google Cloud のプロジェクト、Amazon Web Service のアカウントとも近い概念です。 ↩
-
Role Based Access Control ↩
-
org-admin、org-edit、org-viewの 3 つが提供されています。 ↩ -
組織管理者に限り、ルートネームスペースとすべてのサブネームスペースで
org-adminにマッピングされます。 ↩
PFCP リリースノート
2026年6月
 MOCO によるリレーショナルデータベースの実行が利用可能になりました(ドキュメント)
MOCO によるリレーショナルデータベースの実行が利用可能になりました(ドキュメント)
2026年5月
- KEDA によるジョブの自動水平スケーリングが利用可能になりました(ドキュメント)
 Kubernetes: 全拠点の全てのクラスタで Kubernetes v1.35 へのアップグレードを実施しました(ドキュメント)
Kubernetes: 全拠点の全てのクラスタで Kubernetes v1.35 へのアップグレードを実施しました(ドキュメント)
2026年4月
- 機密データを GitOps 手法で管理するための Kubernetes カスタムリソース「SealedSecret」が利用可能になりました(ドキュメント)
2026年2月
- Kubernetes: ブラウザでリソースを確認・操作できるダッシュボード「Headlamp」が利用可能になりました(ドキュメント)
- PFCP: MN-Core SDK v0.4 をリリースしました(お知らせ)
- Kubernetes: 組織のリソースクオータを Grafana ダッシュボードで確認できるようになりました(お知らせ)
- PFCP: PFCP ポータルが英語で利用できるようになりました(お知らせ)
 Kubernetes: 脆弱性対応のために ingress-nginx バージョンを v1.14.3 に更新しました(お知らせ)
Kubernetes: 脆弱性対応のために ingress-nginx バージョンを v1.14.3 に更新しました(お知らせ)- Kubernetes: GitHub Actions ジョブを実行できるようになりました(ドキュメント)
2026年1月
- Kubernetes: 全拠点の全てのクラスタで Kubernetes v1.34 へのアップグレードを実施しました(ドキュメント)
2025年11月
- PFCP: Ingress の公開範囲を組織の一部ユーザへ限定できるようになりました(お知らせ)
- Kubernetes: 分散バッチ処理を実行するための ParallelJob カスタムリソースが利用可能になりました(ドキュメント)
- Kubernetes: 共有ノードで永続ストレージにファイルシステムが利用可能になりました
- Kubernetes: 脆弱性対応のために runc バージョンを v1.3.3 に更新しました(お知らせ)
2025年10月
- PFCP: ワークスペースにお手もとの Visual Studio Code から接続できるようになりました(ドキュメント)
2025年9月
- Kubernetes: KEDA を利用した外部イベント駆動によるワークロードの自動水平スケーリングが利用可能になりました(ドキュメント)
- Kubernetes: 全拠点の全てのクラスタで Kubernetes v1.33 へのアップグレードを実施しました(ドキュメント)
2025年8月
- Kubernetes: 永続ストレージのスナップショット機能が利用可能になりました(ドキュメント)
2025年7月
 AlertmanagerConfig カスタムリソースを作成しても Alertmanager に設定が反映されていなかった問題を修正しました
AlertmanagerConfig カスタムリソースを作成しても Alertmanager に設定が反映されていなかった問題を修正しました- PFCP: ワークスペースの構成を事前に定義して共有できる「プリセット」機能が利用可能になりました(ドキュメント)
- PFCP: ワークロードをウェブ API として公開する “API Identity-Aware Proxy” 機能が利用可能になりました(ドキュメント)
2025年6月
- Kubernetes: 全拠点の全てのクラスタで Kubernetes v1.32 へのアップグレードを実施しました(ドキュメント)
2025年5月
- Kubernetes: 共有ノード用に
shared-standardとshared-best-effortの 2 つの PriorityClass が追加されました(ドキュメント) - PFCP: PFCP ポータルからワークスペースを作成する際に Pod の PriorityClass が選択可能になりました
2025年4月
- MN-Core: MN-Core SDK v0.2 がリリースされました(更新内容はコンテナイメージ内の
/opt/pfn/pfcomp/RELEASE_NOTES.mdをご参照ください) - Kubernetes: 新しい計算ノードの種類として「共有ノード」が利用可能になりました(ドキュメント)
- Kubernetes: ワークスペース内の PersistentVolume を残したまま計算リソースを節約する「ワークスペース休止」機能が利用可能になりました(ドキュメント)
2025年3月
- PFCP: PFCP ポータルにおいて PFCP 提供コンテナイメージの一覧が閲覧可能になりました(ドキュメント)
2025年2月
- Kubernetes: ブラウザから使えるインタラクティブな作業環境を提供する「ワークスペース」機能が利用可能になりました(ドキュメント)
- Kubernetes: 全拠点の全てのクラスタで Kubernetes v1.31 へのアップグレードを実施しました(ドキュメント)
- Kubernetes: 組織管理者が Kubernetes Role リソースの操作が可能になりました(ドキュメント)
2024年12月
- Kubernetes: PFCP ポータルにおいて組織で利用可能な専有ノードの一覧が閲覧可能になりました
- PFCP: 組織に属するユーザをグループにまとめる「ユーザグループ」機能が利用可能になりました(ドキュメント)
2024年11月
- Kubernetes: 全拠点の全てのクラスタにおいて GitOps ツールの Flux が利用可能になりました(ドキュメント)
2024年10月
- Kubernetes: SR1-01 クラスタの永続化ストレージにおいて同一組織内の Namespace であればファイルストレージが共有できるようになりました(ドキュメント)
2024年9月
- Kubernetes: 全拠点の全てのクラスタで Kubernetes v1.30 へのアップグレードを実施しました(ドキュメント)
2024年6月
- Kubernetes: SR1-01 クラスタで永続ストレージが利用可能になりました(ドキュメント: ファイルストレージを使用する、ブロックストレージを使用する)
- Kubernetes: 組織で利用可能な専有ノードの情報を
kubectl get reservednodeコマンドで確認可能になりました(ドキュメント) - Kubernetes: 全拠点の全てのクラスタで Kubernetes v1.29 へのアップグレードを実施しました(ドキュメント)
2024年4月
メンテナンスポリシ
計画メンテナンスおよび緊急メンテナンスのポリシについて説明します。
定期メンテナンスのポリシ
PFCP では信頼性を維持するために定期的な計画メンテナンスを実施します。
| 項目 | 内容 |
|---|---|
| 実施日 | 毎月第一月曜日 |
| 実施日の告知 | 実施予定の1か月前まで (第一月曜日から変更がある場合のみ告知) |
| 実施内容の告知 | 実施日の2週間前まで (メンテナンスを実施する場合のみ告知) |
Kubernetes バージョンのアップグレードのポリシ
Kubernetes クラスタの安定性、パフォーマンス、セキュリティの向上を目的にマイナーバージョンアップグレードを定期的に実施しています。
| 項目 | 内容 |
|---|---|
| 実施頻度 | 4ヶ月毎 |
| 採用するバージョン | 最新のマイナーバージョンから1つ前のマイナーバージョン (例: 最新が v1.30 の場合、採用するバージョンは v1.29) |
| 実施日の告知 | 定期メンテナンスの実施内容として告知 |
アップグレードおよびその他メンテナンスのクラスタとワークロードへの影響
クラスタアップグレードなどの計算ノードの一時的な停止を伴うメンテナンスのユーザ影響を説明します。
クラスタと計算ノードへの影響
- クラスタの操作が一時的に不安定になります
- ユーザ割り当ての専有ノードのうち、アップグレード実施中の計算ノードが一時的に使用できなくなります
- 専有ノードの契約台数が 4 台未満の場合は 1 台ずつ、4 台以上の場合は最大 25%(小数切り捨て)が一時的に使用できなくなります
- 1 台のみ契約されている場合は一時的に利用できるノードがなくなります
- 共有ノードは 25%(小数切り捨て)が一時的に使用できなくなります
ワークロードへの影響
- 計算ノードのアップグレード実施に伴い該当ノードで実行中のワークロード(Kubernetes Pod)は削除されます
- 削除されたワークロードは、再スケジューリングポリシに基づき、別の計算ノードまたは同ノードで自動的に再作成されます
- Deployment や Job などの上位リソースを使わずにユーザにより直接作成された Pod(Bare Pod)は自動的に再作成されません
- 直接 Pod リソースを作成することは避けることを推奨します
Warning
データ保持に関する注意点
- ワークロードが保持するデータのうち、永続ストレージに保存されていないデータは失われることに注意してください
- ローカルメモリ上のデータ、一時的なファイルシステム上のデータなど
- 永続ストレージに保存されているデータは保持されます
計算ノードのメンテナンス実施に備えて推奨される対応
- 計算結果や生成物などの重要なデータは必ず永続ストレージに保存してください
- ワークロードがステートフルな場合は、データの永続化および復旧手順を十分に検討・準備してください
Important
メンテナンスや障害以外にもあらゆる理由でワークロード、プロセスは停止します。重要なデータは必ず永続ストレージに保存してください。
緊急メンテナンスのポリシ
サービスの提供継続が困難またはセキュリティ上の重大な脆弱性が発見されたなどの理由から予定されていないメンテナンスを実施することがあります。 クラスタおよび計算ノード、ワークロードに影響がある場合には事前に実施内容を告知します。
メンテナンス情報を入手する
新しいメンテナンス情報は PFCP お知らせサイト に掲載します。 詳しくは新機能・メンテナンスの通知を参照ください。
計算ノードの障害復旧ポリシ
計算ノードで障害が発生した場合の復旧ポリシについて説明します。
計算ノードの障害
計算ノードが正常に動作していないと判断した場合に障害が発生したとして復旧対応を実施します。下記は正常に動作していないと判断する一例です。
- 計算ノードが搭載するデバイスの一部が機能していない
- 計算ノードとの通信が確立できない
計算ノードの障害復旧ポリシ
計算ノードで障害が発生したと判断した場合には下記のポリシに基づき復旧対応を実施します。
- ユーザへの事前の告知なしに該当計算ノード上のワークロード(Kubernetes Pod)を削除し、計算ノードを再起動します
- 削除されたワークロードは、再スケジューリングポリシに基づき、別の計算ノードまたは同ノードで自動的に再作成されます
- Deployment や Job などの上位リソースを使わずにユーザにより直接作成された Pod(Bare Pod)は自動的に再作成されません
- 直接 Pod リソースを作成することは避けることを推奨します
- 削除されたワークロードは、再スケジューリングポリシに基づき、別の計算ノードまたは同ノードで自動的に再作成されます
- 専有ノードの場合に再起動で復旧が見込めない場合には代替の計算ノードとの入れ替えを行います
計算ノードの障害に備えて推奨される対応
- 計算結果や生成物などの重要なデータは必ず永続ストレージに保存してください
- ワークロードがステートフルな場合は、データの永続化および復旧手順を十分に検討・準備してください
Important
メンテナンスや障害以外にもあらゆる理由でワークロード、プロセスは停止します。重要なデータは必ず永続ストレージに保存してください。
新機能・メンテナンス情報を入手する
PFCP の新しい機能追加・メンテナンスに関する最新情報を入手する方法について説明します。
お知らせサイト
ウェブサイトに最新情報を掲載しています。
RSS リーダを使用して新着情報を購読する
お知らせサイトは RSS フィードを発行しています。RSS リーダを使用して新着情報を購読できます。
- 全カテゴリ: https://pfcomputing.com/news/index.xml
- カテゴリ別
Slack チャンネルで購読するには Add RSS feeds to Slack | Slack を参照ください。
メーリングリスト
準備中です。
PFCP チュートリアル: ワークロードをデプロイする
このページでは、クラスタを使用してサーバのワークロードのデプロイを行い、モニタリングサービスの使用方法を学びます。
事前準備
左カラム「クラスタに接続する」の手順を実行して下記を完了してください。
- PFCP ポータルにログインできている
- クラスタへの接続が構成できている
Namespace の作成
本チュートリアルで使用する Namespace1 を作成します。
Note
Namespace の作成には「組織管理者」の権限が必要です。「一般ユーザ」の権限では Namespace の作成に失敗します。
一般ユーザでの操作の場合は、組織の組織管理者に対して Namespace の作成を依頼してください。
-
ポータルのネームスペースにアクセスします。
-
ネームスペースの作成 画面を開きます。
- クラスタ名: 利用するクラスタを選択
- ネームスペース名:
org-<組織名>--<任意の値>2
-
作成 ボタンをクリックすると、Namespace が作成されます。
-
kubectl コマンド実行時のデフォルトの Namespace として、作成した Namespace を設定します。
$ kubectl config set-context --current --namespace=<作成したNamespace名> -
Namespace が作成されていること、設定が正しいことを確認します。
kubectl get podを実行してください。エラーが出なければ正しく設定されています。エラーが出力された場合は、Namespace が存在することを確認のうえ、実行コマンドが正しいかを再度確認してください。// 正しく設定されている場合 $ kubectl get pod No resources found in <作成したNamespace名> namespace. // 設定に誤りがある場合 $ kubectl get pod Error from server (Forbidden): pods is forbidden: User "oidc:org-<組織名>/<ユーザ名>" cannot list resource "pods" in API group "" in the namespace "<作成したNamespace名>"
ワークロードのデプロイ
PFCP の Kubernetes クラスタを用いて、サンプルの Pod を実行します3。 加えて、作成した Pod をインターネットに対して公開し、ブラウザからアクセスできることを確認します。
なお、サンプルのコンテナイメージとして podinfo を使用しています。
-
以下のコマンドを実行し、podinfo を実行する Deployment を作成します。
$ kubectl create deployment podinfo --image=stefanprodan/podinfo --port=9898 deployment.apps/podinfo created -
Pod の起動を確認します。
$ kubectl get pod NAME READY STATUS RESTARTS AGE podinfo-554c877494-p58gf 1/1 Running 0 25s -
次に、起動した Pod を公開するための Service を作成します。
$ cat << EOF | kubectl apply -f - apiVersion: v1 kind: Service metadata: labels: app: podinfo name: podinfo spec: ports: - name: http port: 8080 protocol: TCP targetPort: 9898 selector: app: podinfo EOF service/podinfo created $ kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE podinfo ClusterIP 10.100.212.250 <none> 8080/TCP 77s -
作成された Service をインターネット公開するために、Ingress を作成します。
$ HOST=podinfo-<任意の名前>.<組織名>.sr1-01.ingress.pfcomputing.com $ kubectl create ingress podinfo-ingress --class=nginx --rule="${HOST}/*=podinfo:8080" ingress.networking.k8s.io/podinfo-ingress created $ kubectl get ingress NAME CLASS HOSTS ... podinfo-ingress nginx <HOSTと同じ値> ... -
ブラウザから
https://<HOSTと同じ値>にアクセスします。podinfo の画面が表示されたら成功です。
モニタリングの確認
PFCP では、Grafana と Prometheus がマネージドサービスとして提供されています。 これらを使用して、作成した Pod のリソース仕様状況を確認します。
-
Grafana のダッシュボードにアクセスします。ポータルのトップページ に表示されているリンクからアクセスできます。
-
左上のハンバーガーアイコンから
Dashboards>kube-prometheus>Kubernetes / Compute Resources / Podと辿ることで、Pod のリソース使用状況を確認できます。 Namespace 及び Pod 名は適切なものをプルダウンで選択します。以下のような画面が確認できます。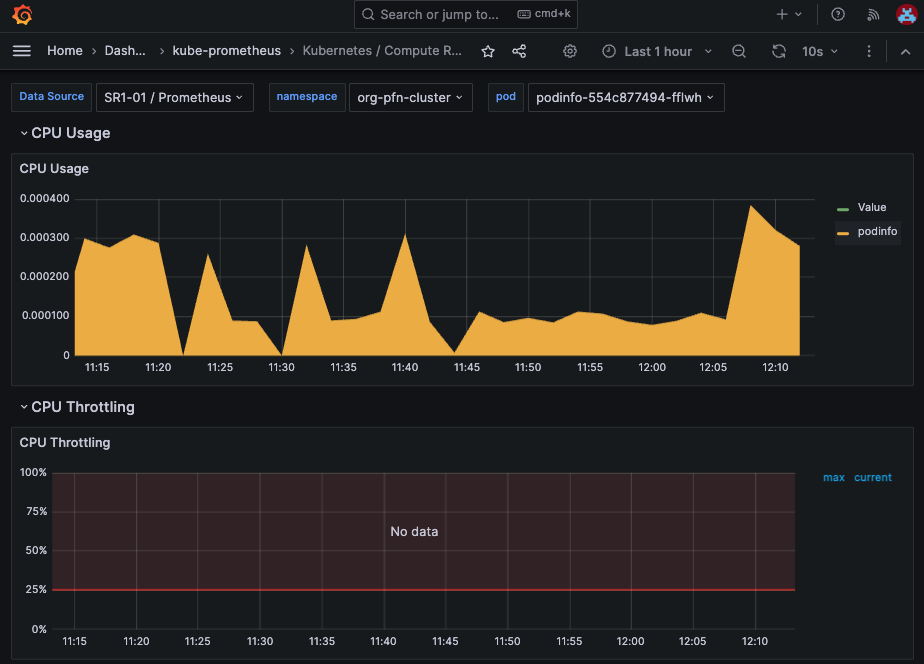
-
Pod で計装されているメトリックについても、Prometheus による収集と Grafana による可視化が可能です。 例として、上記で作成した podinfo Pod のメトリック4を収集します。
以下のServiceMonitorカスタムリソースを作成します。
$ cat << EOF | kubectl apply -f - apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: podinfo spec: selector: matchLabels: app: podinfo endpoints: - interval: 30s port: http path: /metrics EOF servicemonitor.monitoring.coreos.com/podinfo created -
podinfo のスクレイプに成功し、メトリックの収集ができていることを確認します。 Prometheus の WebUI にアクセスし、 上部のタブから
Status>Targetsを選択します。<作成したNamespace名>/podinfo/0がターゲット一覧に表示され、ステータスがUpになっていれば、正しくスクレイプできています。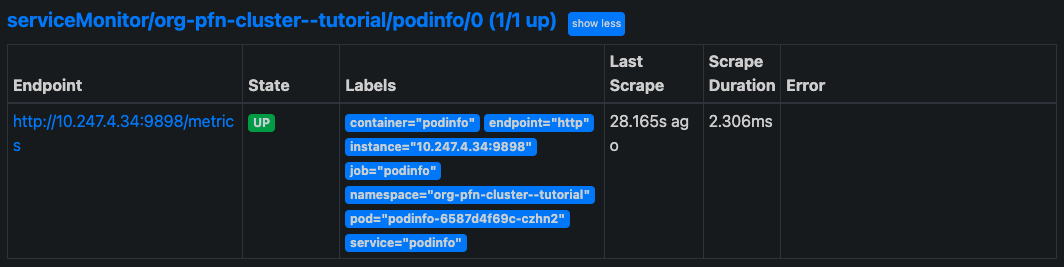
-
収集したメトリックは、Grafana で可視化できます。 Grafana のダッシュボードを開き、左上のハンバーガーアイコンから
Exploreを選択します。 例として以下の PromQL クエリを実行すると、/metricsendpoint がコールされた回数が時系列表示されます。sum by (pod) (rate(promhttp_metric_handler_requests_total{namespace="<作成したNamespace>", job="podinfo"}[$__rate_interval]))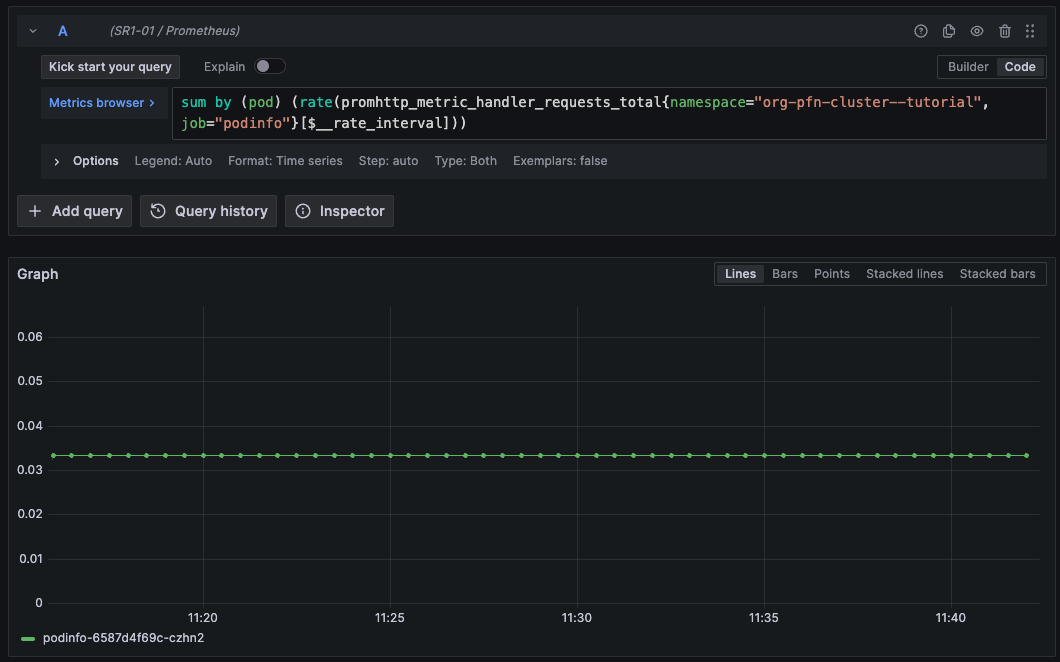
-
作成した Namespace は、PFCP ではサブネームスペースとして扱われます。詳しくは 用語集 をご確認ください。 ↩
-
作成済の Namespace と異なる接尾辞をつける必要があります。複数人でチュートリアルを実施する場合は、ユーザ名の使用を推奨します。 ↩
-
podinfoは、
/metricsでPrometheus用のメトリックを提供しています。 ↩
PFCP チュートリアル: MN-Core を PyTorch から使用する
このドキュメントでは、MLSDK(Machine Learning Software Development Kit)を使用して MN-Core を使用する方法を説明します。
MLSDK とは
MLSDK は、PyTorch から MN-Core を使用できるようにするためのコンパイラ、ランタイムソフトウェアスタック、ドキュメントを含むソフトウェア開発環境です。 名前に「Machine Learning(ML)」とありますが、機械学習分野以外の高速な計算処理を行うソフトウェアの開発にも使用できます。
環境を構築する
インタラクティブな作業環境をクラスタ上に作成する「ワークスペース」機能を使用して環境を構築します。
- ポータルの ワークスペースページ にアクセスし、新規作成 ボタンをクリックします
- フォームを入力し、作成 ボタンをクリックします
| 項目名 | 値 |
|---|---|
| ネームスペース | 組織のルートネームスペースを選択してください |
| ワークスペース名 | 任意の名前を入力してください |
| 所有者 | 個人ごとに隔離 |
| プリセット | default |
| 優先度クラス | (unspecified)(専有ノードを使用)共有ノードを使用する場合は shared-best-effort を選択ください |
| CPU | 7000m |
| Memory | 125Gi |
| MN-Core 2 | 1 |
Note
永続ストレージを追加する
永続ストレージをマウントしていないパスに配置されたファイルの変更は、永続化されずに失われてしまいます。 変更を永続化する際は、「永続ストレージを追加」から新規ストレージを払い出し、
/dataなどにマウントしてファイルを保存してください。
環境にアクセスする
作成したワークスペースの URL 列にあるリンクをクリックして作業環境(JupyterLab)にアクセスします。
Note
ワークスペースの作成には時間がかかる場合があります。
しばらく時間が経過しても作成が完了しない場合はフォームで入力した値が間違っていた可能性があります。もう一度やり直してみてください。
JupyterLab の「Launcher → Other / Terminal」のボタンをクリックし、ターミナルを開きます。
ターミナル上で次のコマンドを実行して環境に接続された MN-Core 2 デバイスを確認できます(割り当てられたデバイスによって異なる値が出力されます)。
$ gpfn3-smi list
0: mnc2p28s0
何も表示されない場合は、ワークスペースの構成に間違いがないかどうか再確認してください。
MLSDK チュートリアルを開始する
MLSDK documentation を参照してチュートリアルを開始します。
MLSDK チュートリアルのドキュメントは、コンテナイメージにも同梱されていますので、そちらでも参照できます。
$ cat /opt/pfn/pfcomp/codegen/MLSDK/README.md
環境を削除する
使用が終了した環境はポータルページで削除します。
- ポータルの ワークスペースページ にアクセスします
- 削除するワークスペースの ⋯ ボタンから「削除」をクリックします
PFCP チュートリアル: クラウドストレージのデータをクラスタに取り込む
このページでは、クラウドストレージにあるデータを PFCP に持ち込むための手順を解説します。
ここでは一例として、ユーザが管理する AWS S3 に保存されているデータを PFCP 上の Persistent Volume にコピーします。
事前準備
左カラム「クラスタに接続する」の手順を実行して下記を完了してください。
- PFCP ポータルにログインできている
- クラスタへの接続が構成できている
また、AWS アカウントと、データを同期させる対象の S3 バケットが必要です1。
パブリッククラウドと ID 連携を構成し、データをコピーする
AWS 側の設定
ここでは sr1-01 拠点を利用している場合の設定を説明します。他の拠点を利用している場合はドメイン名等を適宜読み替えてください。
-
アクセスしたい AWS アカウント内に OIDC プロバイダを作成します2。
- プロバイダ(発行者)URL は 拠点と計算ノード を参照してください。
- 許可するオーディエンス:
sts.amazonaws.com
-
AWS へのアクセスに使用する IAM ロールを作成します。この IAM ロールは、ID 連携により Kubernetes ServiceAccount に紐づけて使用します。 ここでは
data-transfer-sr1-01という IAM ロールを作成します。 -
ID 連携による紐づけを許可するために、IAM ロールを引き受けさせる Kubernetes ServiceAccount を指定して、以下のような信頼ポリシを構成します3。 ServiceAccount は、既存のものを指定するか、後ほど新たに作成します。ここでは
data-transfer-saという ServiceAccount を作成します。{ "Version": "2012-10-17", "Statement": [{ "Sid": "", "Effect": "Allow", "Principal": { // 前のステップで作成した oidc provider の ARN を指定します。 "Federated": "arn:aws:iam::{aws_account_id}:oidc-provider/token.sr1-01.kubernetes.pfcomputing.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { // このIAMロールを引き受けさせる Kubernetes ServiceAccount 名を指定します。 "token.sr1-01.kubernetes.pfcomputing.com:sub": "system:serviceaccount:<namespace>:data-transfer-sa" } } }] } -
転送したいデータを含んだ S3 のバケットに、特定の IAM ロールからアクセス可能にするポリシを設定します4。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::{aws_account_id}:role/data-transfer-sr1-01" }, "Action": [ "s3:ListBucket", "s3:GetObject", ], "Resource": [ "arn:aws:s3:::example-bucket", "arn:aws:s3:::example-bucket/*" ] } ] }
Kubernetes クラスタ側の操作
-
ServiceAccount を作成します。データコピーに利用する ServiceAccount の annotations に、S3 のバケットにアクセス可能な AWS IAM ロール
data-transfer-sr1-01を指定します。apiVersion: v1 kind: ServiceAccount metadata: name: data-transfer-sa annotations: aws.id-federation.preferred.jp/role-arn: "arn:aws:iam::{aws_account_id}:role/data-transfer-sr1-01" -
ID 連携が正常に動作していることを確認します。Pod を作成する際に、
spec.serviceAccountNameにこの ServiceAccount を指定します。 Pod には 1 時間が有効期限である AWS のセッショントークンが自動的に設定されます。有効期限が到来すると、AWS SDK は更新されたトークンを自動で読み込み直します。aws sts get-caller-identityコマンドを実行し、セッショントークンが ServiceAccount に紐づいた AWS IAM Role へ AssumeRole できることを確認します。$ kubectl run --rm --overrides='{"spec":{"serviceAccountName": "data-transfer-sa"}}' id-federation-check --image=amazon/aws-cli -- sts get-caller-identity { "UserId": "***********************:botocore-session-1751604047", "Account": "{aws_account_id}", "Arn": "arn:aws:sts::{aws_account_id}:assumed-role/data-transfer-sr1-01/botocore-session-1751604047" } -
データを格納するための永続ストレージ(Persistent Volume Claim、 PVC)を作成します5。
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: data-transfer-pvc spec: resources: requests: storage: 10Gi storageClassName: standard-rwx-<組織名> -
AWS CLI の
s3 syncコマンドでデータをコピーする Job を作成します。 上記で作成した PVC をマウントし、template.spec.serviceAccountNameに、 AWS との ID 連携を有効にしたdata-transfer-saを指定します。<バケット名>、<オブジェクト名>は適切に変更してください。apiVersion: batch/v1 kind: Job metadata: name: data-transfer-job spec: template: spec: serviceAccountName: data-transfer-sa # ID 連携を構成した ServiceAccount を指定 containers: - name: transfer image: amazon/aws-cli command: ["aws"] args: ["s3", "sync", "s3://<バケット名>/<オブジェクト名>", "/mnt/data"] volumeMounts: - mountPath: "/mnt/data" name: my-volume volumes: - name: my-volume persistentVolumeClaim: claimName: data-transfer-pvc restartPolicy: OnFailurekubectl logs job/data-transger-jobを実行し、コマンドが正常に終了していることを確認します。$ kubectl logs job/data-transger-job download: s3://<バケット名>/file1.txt to /mnt/data/file1.txt ... Completed 10 of 10 file(s), 100% done.
クリーンアップ
チュートリアルで作成したリソースをすべて削除します。
kubectl delete job/data-transfer-job
kubectl delete pvc/data-transfer-pvc
kubectl delete serviceaccount/data-transfer-sa
必要に応じて、 AWS 側のリソースも削除します。
MN-Core SDK
MN-Core SDK は MN-Core シリーズを利用するソフトウェアを開発するためのフレームワークです。 MLSDK と HPCSDK の 2 つの SDK で構成されます。
- MLSDK: PyTorch プログラムから MN-Core シリーズを利用するための SDK です。
- HPCSDK: C/C++ プログラムから MN-Core シリーズを利用するための SDK です。
それぞれの SDK のドキュメントは、以下からご確認ください。
MLSDK
HPCSDK
Coming soon.
PFCP のロール
PFCP で利用可能なロールと、各ロールで利用できる操作を説明します。
ロールの種類
PFCP には、 組織管理者 と 一般ユーザ の 2 種類のロールがあります。
組織管理者
- 所属組織のすべての操作が可能です。
- Kubernetes クラスタのルートネームスペースとすべてのサブネームスペースに対して、Kubernetes 標準ロール の
admin相当の権限を持ちます。
一般ユーザ
- 所属組織の Kubernetes クラスタを利用できます。
- Kubernetes クラスタのルートネームスペースに対して、Kubernetes 標準ロール の
edit相当の権限を持ちます。 - Kubernetes クラスタのサブネームスペースに対しては、初期状態では権限を持ちません。RoleBinding による権限の付与が必要です。
- ユーザ管理操作はできません。
利用可能な操作一覧
クラスタ利用
| 操作 | 組織管理者 | 一般ユーザ |
|---|---|---|
| kubectl のセットアップ | o | o |
| [Kubernetes リソースの操作] | ||
| ルートネームスペース: Kubernetes 標準ロールの admin 相当1 | o | |
| ルートネームスペース: Kubernetes 標準ロールの edit 相当2 | o | o |
| サブネームスペース: Kubernetes 標準ロールの admin 相当1 | o | |
| サブネームスペース: RoleBinding により個別に権限付与 | N/A | o3 |
| サブネームスペースの作成・削除 | o | |
| リソースクオータの確認 | o | o |
ユーザ管理
| 操作 | 組織管理者 | 一般ユーザ |
|---|---|---|
| ユーザの招待・削除 | o | |
| ユーザの権限変更 | o | |
| ユーザグループの作成・削除 | o | |
| ユーザグループへのユーザの追加・削除 | o | |
| ユーザグループと外部認証基盤との連携作成・削除 | o |
-
Kubernetes 標準の
adminとは一部異なり、一部リソースの権限削除および PFCP で利用しているカスタムリソースの権限追加がされています。org-adminという ClusterRole で定義されています。権限の詳細は、各リソースごとのドキュメントページをご確認ください。 ↩ ↩2 -
org-adminと同様、Kubernetes 標準のeditとは一部異なります。org-editという ClusterRole で定義されています。権限の詳細は、各リソースごとのドキュメントページをご確認ください。 ↩ -
RoleBinding で紐づける Role により、付与される権限が異なります。RoleBinding の詳細は、権限設定(RBAC) をご確認ください。 ↩
組織のユーザを管理する
PFCP では、組織管理者が組織に属するユーザの管理をおこないます。
PFCP におけるユーザの管理には以下の 2 つの方法があります。
- ポータル上でのユーザの直接管理
- 外部認証基盤との連携によるグループ単位の管理
ユーザの管理
ご利用の組織へ、直接ユーザの招待、ロール変更、削除をおこなう方法を説明します。
Note
直接招待を行うアカウントは、Google の個人アカウントもしくは Google Workspace アカウントのみ使用できます。
Warning
ユーザに対するロールやユーザグループの変更操作が、既存のログイン済みユーザのセッションに反映されるまで、時間がかかることがあります。 再ログインやブラウザクッキーの消去を試してください。
ユーザを招待する
- ポータルの ユーザ管理ページ にアクセスし、招待メールを送る ボタンをクリックします。
- 招待したいユーザの Eメール と ロール を入力し、招待メールを送る ボタンをクリックします。
- 送信した招待は、受諾待ち一覧 に表示されます。招待メールが受理されると、一覧から消えます。
- 招待が期限切れになってしまった場合は再送してください。
ユーザのロールを変更する
- ポータルの ユーザ管理ページ にアクセスし、ユーザ一覧 を表示します。
- ロールを変更したいユーザを選択し、ロールを変更します。
- ログインしているユーザ自身のロールは変更できません。
ユーザを組織から削除する
- ポータルの ユーザ管理ページ にアクセスし、 ユーザ一覧 を表示します。
- 削除したいユーザを選択し、組織メンバーから削除します。
- 削除したユーザを元に戻したい場合は、再度招待が必要です。
- ログインしているユーザ自身は削除できません。
ユーザグループの管理
組織に属するユーザをグループにまとめることができます。 グループ単位での管理により、ネームスペースに対する権限管理を効率化します。 また、外部認証基盤とユーザグループとを連携させることにより、ご利用の組織のアカウントを連携させることが可能です。
権限管理については、権限設定(RBAC) をご確認ください。
ユーザグループへの所属
ユーザはユーザグループに 2 通りの方法で所属できます。どちらの方法でも、ユーザはグループに所属しているものと扱われます。
- ユーザグループへの直接の所属
- ポータル上で、ユーザをユーザグループに追加します。
- ユーザグループと外部認証基盤のグループの連携
- ユーザグループを外部認証基盤のグループと連携させることで、外部認証基盤のグループに所属するユーザを自動的にユーザグループに追加します。
ユーザグループを作成する
- ポータルの ユーザグループ管理ページ にアクセスし、新規作成 ボタンをクリックします。
- フォームを入力し、作成 ボタンをクリックします。
ユーザグループを削除する
- ポータルの ユーザグループ管理ページ にアクセスします。
- 削除したいグループを選択し、削除 ボタンをクリックします。
ユーザグループにユーザを追加する
- ポータルの ユーザグループ管理ページ にアクセスし、編集したいグループを選択します。
- メンバー追加 セクションで追加したいユーザを選択し、追加 ボタンをクリックします。
- 追加するユーザは、まず組織に招待し受諾されている必要があります。
Note
グループへの所属が Kubernetes クラスタへの接続情報に反映されるまでには、最大 1 時間かかります。
ユーザグループからユーザを削除する
- ポータルの ユーザグループ管理ページ にアクセスし、編集したいグループを選択します。
- メンバー セクションで削除したいユーザを選択し、選択したメンバーを外す ボタンをクリックします。
ユーザグループと外部認証基盤との連携を作成する
- ポータルの 外部認証連携ページ にアクセスします。
- 外部認証基盤のグループ ID と PFCP のグループ名 を入力し、グループ連携を追加 ボタンをクリックします。
- PFCP のグループは先に作成しておく必要があります。
ユーザグループと外部認証基盤との連携を削除する
- ポータルの 外部認証連携ページ にアクセスします。
- 削除したい連携を選択し、選択したグループ連携を削除する ボタンをクリックします。
PFCP ポータルにログインする
PFCP では、Kubernetes クラスタに接続するための認証情報の取得や、各種管理機能を扱うためのポータルを提供しています。
初回ログイン
Note
このセクションでは、メールアドレスを使用する標準的なログイン方法を説明します。 組織によって異なるログイン方法となることがあります。詳細は、組織管理者にお問い合わせください。
- 組織管理者にユーザの招待を依頼します。
- 招待メールを受領したら、メール本文の ACCEPT INVITATION ボタンをクリックします。
- 招待内容の確認画面が表示されます。組織名と招待メールの送信者が正しいことを確認し、 続ける をクリックします。
- 招待メールを受領したメールアドレスを使用してログインします。
- ログイン後、組織名の入力画面が表示されるので、招待された組織名を入力します。
- ログイン状態の再確認が行われたあと、ポータルに自動で遷移します。
2回目以降のログイン
- ポータル にアクセスします。
- 組織名の入力画面が表示されるので、ご利用の組織名を入力します。
- 登録されたメールアドレスを使用してログインします。
クラスタに接続する
このページでは、Kubernetes クラスタに接続する方法を説明します。
クラスタの操作に使用するコマンドラインツールのインストール
Kubernetes のコマンドラインツールである kubectl ツールを用いて、Kubernetes クラスタに接続します。
kubectl ツールのインストールは、公式ドキュメントを参考に実施します。
Kubernetesクラスタの接続情報を設定
- ポータルのkubectlのセットアップ にアクセスします。
- クラスタ名 のドロップダウンから使用したいクラスタを選択します。
- 認証情報の取得 をクリックし、出力されたコマンドをコピーしてターミナルで実行します。
Note
複数の環境からクラスタに接続する
複数の環境からクラスタに接続する場合は、環境ごとに複数回 認証情報の取得 をクリックしてそれぞれ異なるコマンドを生成して使用してください。
同じ認証情報を複数の環境で使いまわした場合、認証情報が無効化されて次のようなエラーと共にクラスタの操作に失敗します。
failed to refresh token: oauth2: "invalid_grant" "Unknown or invalid refresh token."認証情報が無効化された場合は改めて認証情報を取得し直して再設定する必要があります。
接続確認
kubectl auth whoami を実行し、Username にご自身のメールアドレス、Groups にご利用の組織名のグループが表示されることを確認します。
$ kubectl auth whoami
ATTRIBUTE VALUE
Username oidc:<ご利用の組織名>/<ご利用のメールアドレス>
Groups [oidc:<ご利用の組織名> system:authenticated]
Kubernetes の基礎を学ぶ
PFCP はオープンソースのコンテナオーケストレーションプラットフォームである Kubernetes をベースに構成されています。このサイトのドキュメントは Kubernetes の基本的なコンセプトや用語を理解していることが前提になっています。まだ Kubernetes に慣れていない方は、ここで Kubernetes の基礎を確認してください。また、公式サイトや書籍を通じて Kubernetes についてさらに深く知ることで、PFCP をより効果的に利用できるようになります。
Kubernetes の概要
Kubernetes は、Cloud Native Computing Foundation(CNCF)にホストされたオープンソースのコンテナオーケストレーションプラットフォームです。コンテナ化されたアプリケーションの展開、スケーリング、可用性の管理を自動化するためのツールで、この分野の標準として広く採用されています。
詳細は、Kubernetes の公式ドキュメントを参照ください。
Note
PFCP は Kubernetes をベースとして深層学習・AI ワークロード向けのクラウドサービスとして構成されています。提供するクラスタはマネージドで、ユーザがクラスタ自体を運用する必要がありません。
クラスタとノード
クラスタはワークロードを実行・管理するためのマシン群の集合体です。ユーザからみると 1 つのまとまった計算リソースとして扱えます。
ノードはクラスタを構成する 1 つのマシンで、その実体は一般的な仮想マシンや物理マシンです。
Kubernetes はユーザからワークロードのデプロイが指示されると、ワークロード定義に記述された CPU やメモリ、MN-Core といったデバイスの要求数を確認し、適切なノードにワークロードをスケジュール、実行します。
Note
PFCP ではユーザのワークロードを実行するためのノードのことを「計算ノード」と呼びます。
Namespace
Kubernetes Namespace は 1 つのクラスタを論理的に分割するための機能です。 Kubernetes ではリソースの名前が Namespace 内でユニークである必要があります。 ステージングや本番などの環境を分割したり、複数のチームやプロジェクトから使用する場合に Namespace を使うことでリソースの管理が容易になります。
詳細は、Kubernetes の公式ドキュメントを参照ください。
Note
一般に Kubernetes Namespace の管理にはクラスタ全体の管理者権限が必要ですが、PFCP では Kubernetes カスタムアドオンを使用して組織管理者が Namespace を管理できます。
Pod
Kubernetes ではワークロードを Pod という 1 つ以上のコンテナで構成します。Pod は Kubernetes におけるデプロイ可能な最小単位です。 1 つの Pod に含まれるコンテナは必ず同一のノード上で実行され、同じネットワークとストレージを共有しながら動作します。
詳細は、Kubernetes の公式ドキュメントを参照ください。
コンテナとコンテナイメージ
コンテナはシステムの他の部分とは分離して一連のプロセスを実行する技術です。コンテナはホストや他のプロセスから切り離されるため、環境依存による問題を引き起こしにくく、どの環境でも同じように実行できます。
コンテナを実行するために必要なコードやライブラリ、ランタイムはコンテナイメージと呼ばれるパッケージに含める必要があります。 コンテナイメージはコンテナイメージレジストリと呼ばれるサービスに保存され、配信されます。
詳細は、Kubernetes の公式ドキュメントを参照ください。
Note
PFCP の専用コンテナイメージレジストリは、MN-Core の使用に必要なファイルやソフトウェアを含むコンテナイメージを提供しており、すぐに MN-Core の使用を開始できます。
Note
PFCP ではユーザ自身がビルドしたコンテナイメージをクラスタで使用するためのコンテナイメージレジストリを提供していません。 外部のコンテナイメージレジストリサービスをご利用ください。
Pod を管理する上位のリソース: Deployment、StatefulSet、Job、CronJob…
Kubernetes は Pod を管理するより上位のリソースタイプを提供し、様々な種類のワークロードをサポートします。
- Deployment: クラスタのノード間で分散された複数の Pod レプリカを実行します。失敗した Pod や応答しなくなった Pod は自動的に置き換えられるため、サービスを可用性高く運用する用途に向いています。
- StatefulSet: 各 Pod レプリカに一意の ID を保持して実行します。ステートフルなアプリケーションの実行に役立ちます。
- Job: 1 つ以上の Pod レプリカを作成して指定された数の Pod が正常に終了するまで、Pod の作成と実行を再試行し続けます。ワンショットの学習を行う用途に向いています。
- CronJob: Linux
cronのように指定のスケジュールに基づき Kubernetes Job を作成します。
Warning
上位リソースを使わずにユーザにより直接作成された Pod(Bare Pod)はノードの障害などが理由で停止された場合に自動的に他のノードで再実行されません。 基本的に直接 Pod を作成することは避け、上位のリソースを使用してください。
詳細は、Kubernetes の公式ドキュメントを参照ください。
Note
PFCP では深層学習・AI ワークロードの実行に便利な Kubernetes 組み込みではないカスタムのリソースも提供しています。カスタムのリソースについては、本ユーザガイドをご参照ください。
Service
Service は一連の Pod に固定されたネットワークエンドポイントを提供します。 Pod は実行するたびに異なる IP アドレスが自動先に割り当てられるため、直接 Pod に対しては安定してアクセスできません。
加えて、Kubernetes はクラスタ内部のアドレス解決用に組み込みの DNS を提供し、Service の名前を使用したサービスディスカバリ機能を提供します。Service の名前を使用して安定してワークロードにアクセスできます。
詳細は、Kubernetes の公式ドキュメントを参照ください。
Ingress
Ingress はクラスタ外から Kubernetes Service に対しての HTTP/HTTPS アクセスを提供します。ホスト名やパスに応じたリクエストの振り分けが可能です。
詳細は、Kubernetes の公式ドキュメントを参照ください。
Note
PFCP では、Ingress を使用してサービスにインターネットから安全に公開できます。 ワークロードをウェブ API として公開する または ワークロードをウェブアプリとして公開する を参照してください。
永続ストレージ
実行中の Pod に保存されたデータは Pod の停止とともに失われます。 Pod の存続期間を超えてデータを保持する必要がある場合には、PersistentVolumeClaim を使用して永続ストレージをプロビジョニングし、Pod にマウントして使用できます。
詳細は、Kubernetes の公式ドキュメントを参照ください。
マニフェストファイル
クラスタ上に作成・管理したいリソースの状態(構成)を記述した YAML または JSON 形式のファイルをマニフェストファイルと呼びます。一般に YAML 形式で記述されます。
Kubernetes ではクラスタに対してワークロードをデプロイするにはコマンドラインツールなどから命令的に作成・更新する方法と、マニフェストファイルを使用して宣言的に作成・更新する方法の 2 つがあります。 命令的な方法は一時的に操作する場合に素早く行える利点があります。一方で再現性が低いため、多くの場合に望ましい状態をファイルとして管理できるマニフェストファイルを使用した宣言的な方法の使用を推奨します。
詳細は、Kubernetes の公式ドキュメントを参照ください。
Namespace でクラスタを論理的に分割する
Kubernetes では、Namespace リソースを作ることで複数の作業空間を構築し、各作業空間ごとに独立したリソース管理ができます。 検証・本番環境のように権限やネットワーク接続性の要件が異なる環境を運用したい場合や、複数のチームで利用する場合に有用です。
PFCP では、Namespace リソースの作成機能を提供しています。 ただし、PFCP の Kubernetes クラスタはマルチテナント型で構成されているため、Namespace リソースの作成に関して一般の Kubernetes クラスタとは異なる以下の制約があります。
Warning
ネームスペースの制約
- 各組織には、ルートネームスペースとして 1 つの Namespace リソースが提供されます。
- 追加の Namespace リソースは、このルートネームスペースに従属するサブネームスペース1として作成します。
- ルートネームスペースのリソース名は、
org-<組織名>です。- サブネームスペースのリソース名は、
org-<組織名>--が接頭辞として付きます。- ルートネームスペースは、PFCP の全クラスタで事前に作成されます。削除できません。
- サブネームスペースは、PFCP の各クラスタごとに個別に作成します。削除可能です。
- kubectl などを利用して直接 Namespace リソースを作成することはできません。2
- サブネームスペースに従属するサブネームスペース(孫ネームスペース)を作成することはできません。
以下では、サブネームスペースを管理する方法を説明します。
サブネームスペースの作成
以下の手順で、サブネームスペースを作成します。
- ポータルのネームスペースにアクセスします。
- ネームスペースの作成 画面を開きます。
- クラスタ名、ネームスペース名、説明を入力します(説明は任意項目です)。
- 組織内の他の Namespace からの通信を許可しない場合は、 オプション2にチェックを入れてください。
- 作成 ボタンをクリックすると、サブネームスペースが作成されます。
作成したサブネームスペースは、通常の Namespace リソースとして使用できます。
# サブネームスペース `org-<組織名>--foo` を作成した場合
$ kubectl get all -n org-<組織名>--foo
No resources found in org-<組織名>--foo namespace.
組織管理者は、作成したサブネームスペースに対して org-admin Role の権限が自動で付与されます。
一般ユーザは、サブネームスペースに対して自動での権限付与がされないため、RoleBinding を作成して権限を付与する必要があります。
RoleBinding の詳細は、権限設定をご確認ください。
サブネームスペースの変更
- ポータルのネームスペースにアクセスします。
- 変更したいサブネームスペースの変更画面を開き、設定を修正します。クラスタ名、ネームスペース名は変更できません。
- 更新 ボタンをクリックすると、サブネームスペースが変更されます。
Note
ルートネームスペースの変更はできません。
サブネームスペースの削除
- ポータルのネームスペースにアクセスします。
- 削除したい Namespace を選択し、削除します。
Warning
サブネームスペースを削除すると、Namespace リソース内で作成された全リソースが削除されます。
Note
ルートネームスペースの削除はできません。
参考: コマンドラインツールでサブネームスペースを操作する
サブネームスペースの機能は、Hierarchical Namespaceの SubnamespaceAnchor カスタムリソースで実現しています。 kubectl-hnsプラグインを導入すると、サブネームスペースの操作をターミナルから行えます。
サブネームスペースの作成
# org-<組織名>--foo サブネームスペース を作成する
$ kubectl hns create org-<組織名>--foo -n org-<組織名>
Successfully created "org-<組織名>--foo" subnamespace anchor in "org-<組織名>" namespace
階層構造の閲覧
$ kubectl hns tree org-<組織名>
org-<組織名>
└── [s] org-<組織名>--foo
Namespaceの削除
$ kubectl delete subnamespaceanchor org-<組織名>--foo -n org-<組織名>
-
サブネームスペース機能を提供するために、Hierarchical Namespaceを採用しています。 ↩
-
Hierarchical Namespace のカスタムリソースである SubnamespaceAnchor を使用すれば、サブネームスペースとして Namespace リソースを作成できます。 ↩ ↩2
ユーザのクラスタアクセス権限を管理する
PFCP では、Kubernetes における Role/RoleBinding を用いた Role Based Access Control(RBAC)が利用できます。 RoleBinding を作成することで、Role に定義された権限をユーザやグループに付与できます。
Note
以下を読み進める前に PFCP のロール を確認し、PFCP で利用可能なロールについて把握してください。
PFCP で標準提供するロールとグループ
以下の 3 つの ClusterRole1 が利用できます。
org-view- ユーザのワークロードを閲覧するために必要な権限を有します。
org-editorg-viewの権限に加えて、ユーザのワークロードを実行するために必要な権限を有します。
org-adminorg-editの権限に加えて、Role/RoleBinding 操作などの管理者権限を有します。
Tip
各 ClusterRole は Kubernetes 標準の
view/edit/adminClusterRole を基として一部リソースの権限削除および PFCP で利用しているカスタムリソースの権限追加がされています。 具体的にどのリソースに対してどの操作が許可されているかについては下記コマンドで参照できます。$ kubectl get clusterrole org-view org-edit org-admin -o yaml
また、以下の 2 つのグループが標準で提供されています。
org-<組織名>(例:org-pfn)- 組織管理者と一般ユーザの両方がこのグループに所属します。
- ルートネームスペースに対してのみ
org-editRole が与えられます。サブネームスペースに対しては Role が付与されません。
org-<組織名>/admin(例:org-pfn/admin)- 組織管理者が所属するグループです。
- ルートネームスペースおよびすべてのサブネームスペースに対して、
org-adminClusterRole が与えられます。
ルートネームスペースは、組織に属するすべてのユーザが org-edit 以上の権限を有しているため、初期設定のままご利用いただけます2。
新規に作成したサブネームスペースについては、一般ユーザは権限をもちません。一般ユーザに権限を付与するには、RoleBinding を作成します。
RoleBinding の作成
RoleBinding は、以下の 2 通りで作成できます。
- グループに対する RoleBinding の作成
- ユーザに対する RoleBinding の作成
サブネームスペースに対して、グループ・ユーザのそれぞれに org-edit の ClusterRole2を付与する方法を説明します。
グループに対する RoleBinding の作成
すべてのユーザに対し、サブネームスペース(org-<組織名>--foo)への権限を付与するには、以下の RoleBinding を作成します。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: org-edit
namespace: org-<組織名>--foo
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: org-edit
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: oidc:org-<組織名>
また、組織のユーザを管理する で作成したユーザグループへ権限を付与できます。
ユーザグループ(ops)に対し、サブネームスペース(org-<組織名>--foo)への権限を付与するには、以下の RoleBinding を作成します。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: org-edit-ops # name は任意です
namespace: org-<組織名>--foo
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: org-edit
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: oidc:org-<組織名>/ops # PFCP のユーザグループ名を指定します。
Note
外部認証基盤との SAML 連携をご利用になりたい場合は、サポートまでお問い合わせください。
ユーザに対する RoleBinding の作成
特定のユーザ(alice@example.com)に対し、サブネームスペース(org-<組織名>--foo)への権限を付与するには、以下の RoleBinding を作成します。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: org-edit-user-alice # name は任意です
namespace: org-<組織名>--foo
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: org-edit
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: oidc:org-<組織名>/alice@example.com
一般ユーザのルートネームスペースに対するワークロード実行権限を削除する
PFCP で標準提供するロールとグループ に記載のとおり、一般ユーザにはルートネームスペースへの org-edit 権限がデフォルトで付与されます。
一般ユーザに対するルートネームスペースへの org-edit 権限付与をやめる場合は、以下のコマンドを実行します。
$ kubectl -n org-<組織名> delete rolebindings org-edit
これにより、一般ユーザはルートネームスペースでの任意のリソース作成とワークロードの実行ができなくなります。
Note
一般ユーザはルートネームスペースの
org-view権限を常に持ち、組織管理者がこの権限を無効化することはできません。
独自の Role を作成する
org-admin ClusterRole には任意の Role をネームスペースに作成する権限が含まれており、組織管理者は独自の権限設定を持つ Role を作成し一般ユーザに付与できます。
例えば Pods の閲覧権限のみを許可する独自の Role は次のようになります。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: pod-view
namespace: org-<組織名>--foo
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
参考リンク
FAQ
Q. 組織管理者権限を使用していますが、クラスタを操作するときは org-edit ロールを使用したいです
組織管理者に付与される org-admin ロールではサブネームスペースや RoleBinding などを操作できる強い権限を持つため、学習ワークロードを実行する際は org-edit ロールを使うことで、誤操作を防止できます。
これは、org-edit ロールが付与された ServiceAccount を作り、その ServiceAccount としてふるまうことで実現できます。
org-<組織名>--foo サブネームスペースを org-edit ロールで操作する場合の手順を、以下に記します。
// `org-<組織名>--foo` ネームスペースに ServiceAccount を作ります。
$ kubectl -n org-<組織名>--foo create sa org-edit-sa
serviceaccount/org-edit-sa created
// 作成した ServiceAccount に `org-edit` ロールを付与します。
$ kubectl -n org-<組織名>--foo create rolebinding org-edit-sa --clusterrole=org-edit --serviceaccount=org-<組織名>--foo:org-edit-sa
rolebinding.rbac.authorization.k8s.io/org-edit-sa created
// `--as system:serviceaccount:<Namespace>:<ServiceAccount>` フラグを付与することで、対象 ServiceAccount になりすまして処理を行います。
// 対象 ServiceAccount になりすませていることを確認します。
$ kubectl --as system:serviceaccount:org-<組織名>--foo:org-edit-sa auth whoami
ATTRIBUTE VALUE
Username system:serviceaccount:org-<組織名>--foo:org-edit-sa
Groups [system:serviceaccounts system:serviceaccounts:org-<組織名>--foo system:authenticated]
// org-admin ロールであれば ResourceQuota を作成することができますが、なりすましているときは作成ができません。
$ kubectl auth can-i create resourcequotas -n org-<組織名>--foo
yes
$ kubectl --as system:serviceaccount:org-<組織名>--foo:org-edit-sa auth can-i create resourcequotas -n org-<組織名>--foo
no
--as フラグを都度追加するのを避けたい場合は、kubeconfig の user フィールドに以下の通り設定を追加することで、デフォルトの設定にできます。
- name: pfcp-<組織名>-<クラスタ名>
user:
+ as: system:serviceaccount:<Namespace>:<ServiceAccount>
auth-provider:
config
-
ClusterRole はどの Namespace からでも利用できるロールです。 ↩
-
一般ユーザに対するルートネームスペースへの
org-editClusterRole の付与が不要な場合には、オプトアウトできます。設定方法は 一般ユーザのルートネームスペースに対するワークロード実行権限を削除する を参照してください。 ↩ ↩2
Namespace 間の通信を制御する
PFCP では、Namespace をまたぐ通信は以下のポリシーに従い制御されます。
Warning
Namespaceをまたぐ通信のポリシー
- 異なる組織の Namespace をまたいだ通信は、全て拒否されます。
- 同一組織の Namespace をまたいだ通信は、デフォルトでは全て許可されます。
- 通信を拒否するポリシーを任意に追加できます。PFCP サービス側で拒否されている通信は許可できません。
拒否したい通信のポリシーを追加するには、CiliumNetworkPolicy カスタムリソース1 2を使用します。 CiliumNetworkPolicy を使用した拒否ポリシーを追加する例として、Namespace 外からの内向きの通信を拒否する方法を説明します。
CiliumNetworkPolicyによるNamespace外からの内向き通信の拒否
隔離したい Namespace 内に CiliumNetworkPolicy リソースを作成することで、他の Namespace からの通信を拒否します。本番ワークロードを実行する Namespace において、他の Namespace からのアクセスを禁止したい場合に有用です。
例として、下記のリソースをorg-<組織名> Namespace に作ると、同一 Namespace 内の通信および org-<組織名>--foo Namespace からの通信のみ許可されます。
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: "deny-except-org-<組織名>--foo"
namespace: "org-<組織名>"
spec:
endpointSelector: {}
ingressDeny:
- fromEndpoints:
- matchExpressions:
- key: k8s:io.kubernetes.pod.namespace
operator: NotIn
values: ["org-<組織名>", "org-<組織名>--foo"]
spec.ingressDeny に加えて、spec.egressDeny も使用できます。特定の宛先への外向きの通信を拒否したい場合は、 spec.egressDeny をご利用ください。
なお、spec.ingressおよびspec.egressは使用できません。拒否されている宛先との通信の許可はできません。
サブネームスペース作成時の内向き通信遮断オプションについて
ポータルからサブネームスペースの作成・変更を行う際に、オプションを有効にすることで、他の Namespace からの通信を全て拒否する CiliumNetworkPolicy を作成できます。 本番ワークロードの実行環境など、他の Namespace から通信できない環境を作るときに利用できます。
この CiliumNetworkPolicy は deny-all-ingress という名前で作成されます。
作成後は、必要に応じて自由に書き換えてポリシーを変更できます。
組織のリソース使用を確認する
PFCP では、Namespace 単位ではなく組織単位でクオータが設定されており、組織内の全 Namespace のリソース合計数に上限が設定されています。 上限を超えてリソースを作成しようとした場合、作成に失敗します。
ポータルのリソースクオータ から、使用中のリソースの合計および使用上限を確認できます。
Note
上限の緩和をリクエストしたい場合は、サポート窓口までご連絡ください。
リソースクオータを確認する
組織内 Namespace を合算したリソースクオータを実現するために、PFCP では Hierarchical Resource Quota の機能を使用しています。 以下の方法で Hierarchical Resource Quota の上限と使用量を確認できます。
Grafana ダッシュボードでリソースクオータを確認する
PFCP では、Hierarchical Resource Quota の Grafana ダッシュボードを提供しています。 Grafana ダッシュボード の「PFCP > HNC / HRQ / Tenant Resource Hard Limit & Usage」で、組織全体のリソースクオータを確認できます。
コマンドラインツールでリソースクオータを確認する
kubectl-hnsプラグインを導入すると、リソースクオータの確認をターミナルから行えます。
以下のコマンドにより、組織全体のリソース使用状況を確認できます。
$ kubectl get hrq -o yaml -n org-<組織名>
出力される結果の中に .status.hard および .status.used という 2 つの項目があります。
.status.hard: 指定した Namespace 配下のリソースの作成上限を示しています。上限を超えるリソースの作成はできません。.status.used: 指定した Namespace 配下の作成済のリソースの合計数を示しています。
$ kubectl get hrq org-resource-quota -o yaml -n org-<org-name>
apiVersion: hnc.x-k8s.io/v1alpha2
kind: HierarchicalResourceQuota
metadata:
name: org-resource-quota
namespace: org-<org-name>
spec:
hard:
count/configmaps: "100"
count/cronjobs.batch: "100"
...
status:
hard:
count/configmaps: "100"
count/cronjobs.batch: "100"
...
used:
count/configmaps: "3"
count/cronjobs.batch: "0"
...
参考リンク
Namespace のリソース使用を制限する
ResourceQuota リソースを作成することで、Namespace ごとにリソース使用を制限できます。1 2 特定の Namespace での計算リソースの使いすぎを防止し、Namespace 間のリソース配分を調整できます。3
サブネームスペース org-<組織名>--foo にクオータを設定したい場合は、以下のような ResourceQuota を作成します。
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota
namespace: org-<組織名>--foo
spec:
hard:
requests.preferred.jp/mncore2: 4
requests.nvidia.com/gpu: 0
この例では、MN-Core 2 の使用上限を 4 つに限定し、NVIDIA 製の GPU の使用を制限しています。
参考リンク
-
Namespace ごとの ResourceQuota は、自動では作成されません。必要に応じて作成してください。 ↩
-
ルートネームスペースにも ResourceQuota を作成できます。 ↩
-
組織単位のクオータよりも大きな値を設定した場合は、組織単位のクオータが優先されます。 ↩
ストレージ利用可能枠を拡張する
全ての組織には初期構成で 256GiB までのストレージと、 32MB/s、 8KIOPS のベストエフォート I/O 帯域幅が提供されます。
追加のストレージ利用枠を希望する場合は、サポート窓口までご連絡ください。
FAQ
Q. 利用可能枠が余っているはずだが、永続ストレージのプロビジョニングに失敗する
PersistentVolumeClaim を削除することで動的に払い出された PersistentVolume も削除されます。 削除された領域は 12 時間が経過すると再度利用可能な状態となります。 クオータの表示にはすぐに反映されますが、12 時間が経過するまでは再利用できないためご注意ください。
Note
PersistentVolume 削除後にストレージ利用可能枠を急ぎ回復したい場合は、サポート窓口までご連絡ください。
GitOps スタイルの継続的デリバリを構成する
GitOps は、Git を用いてリソース構成情報を宣言的に記述・管理し、その変更を自動でクラスタに適用する手法です。GitOps を取り入れることで、設定の変更点や履歴が明確に追跡可能となり、デプロイプロセスが自動化されることにより手作業が削減されます。
PFCP では、 Kubernetes 上の GitOps を実現する手段として Flux をマネージドサービスとして提供しています。Flux は、Kubernetes 上での GitOps を実現するために使用されるオープンソースの自動化ツールです。リポジトリ内の変更を監視し、それを自動的にクラスタに適用する役割を担います。以下では、実際に Flux を用いて GitOps を可能にする方法について紹介します。
Flux の導入と設定
以下では、単に「リポジトリ」といった際は GitHub リポジトリを指すものとします。
- ポータルのネームスペースにアクセスし、 Flux の Kubernetes リソースを利用するためのネームスペースを作成します。ここでは例として、
org-foo--fluxというネームスペースを作成します。 - 作成した
org-foo--fluxNamespace に、fluxという名前の ServiceAccount を作成します。Flux はこの ServiceAccount を使用してマニフェストを適用します。 ServiceAccount にflux以外の名前を設定すると動作しないので注意が必要です。kubectl create serviceaccount flux --namespace=org-foo--flux - Flux によりマニフェストを適用したい Namespace から Flux が使用する
org-foo--fluxNamespace の Flux ServiceAccount に対して権限を付与します。
Flux によってマニフェストを適用したい Namespace が複数ある場合には、それぞれの Namespace から同様に権限を付与する必要があります。kubectl create rolebinding flux \ # Flux によってマニフェストを適用したい Namespace --namespace=org-foo--target \ # Flux がマニフェストの適用に使用する権限 --clusterrole=org-edit \ # Flux がマニフェストの適用に使用する ServiceAccount --serviceaccount=org-foo--flux:fluxWarning
org-admin が必要なリソースを管理したい場合
--clusterrole=org-editの部分は管理したいリソースの種類に合わせて変更してください。たとえば RoleBinding を Flux で管理したい場合は、fluxServiceAccount に org-admin を付与する必要があります。その場合、一般ユーザによる組織管理者権限を持つfluxServiceAccount を使ったクラスタ操作を避けるために、必ずorg-foo--fluxnamespace の使用者を組織管理者のみに限定してください。 - 以下の
manifest.yamlファイルを記述し、GitRepositoryリソースおよびKustomizationリソースを作成します。この例では、https://github.com/pfcomputing/helloのmainブランチに存在するマニフェストがクラスタに適用されます。apiVersion: source.toolkit.fluxcd.io/v1 kind: GitRepository metadata: name: hello namespace: org-foo--flux spec: interval: 5m url: https://github.com/pfcomputing/hello ref: branch: main --- apiVersion: kustomize.toolkit.fluxcd.io/v1 kind: Kustomization metadata: name: hello namespace: org-foo--flux spec: interval: 10m sourceRef: kind: GitRepository name: hello path: "./kustomize" prune: true timeout: 1m - マニフェストを適用します。
kubectl apply -f manifest.yaml
これらの手順により、設定したリポジトリに存在するマニフェストファイルとクラスタの状態が同期されます。
Flux におけるプライベート Git リポジトリの利用
パブリックなリポジトリだけでなく、プライベートなリポジトリを参照して GitOps を行うことも可能です。以下に手順を示します。
-
Git リポジトリにアクセスするための Secret を作成します。
export KEY_NAME=flux-ssh-key ssh-keygen -t ed25519 -f $KEY_NAME kubectl create secret generic flux-git-secret \ --from-literal=known_hosts="$(ssh-keyscan github.com)" \ --from-file=identity=$KEY_NAME -
cat $KEY_NAME.pubの結果を GitHub の該当リポジトリに読み取り権限を持つデプロイキーとして登録します(GitHub ドキュメント)。 -
manifest.yamlのGitRepositoryを以下のように編集します。- URL をプライベートなリポジトリに書き換え
spec.secretRefフィールドにname: flux-git-secretを指定
apiVersion: source.toolkit.fluxcd.io/v1 kind: GitRepository ... spec: ... url: # 利用したいプライベートリポジトリに書き換え secretRef: # フィールドを追加 name: flux-git-secret -
マニフェストを適用します。
kubectl apply -f manifest.yaml
これらの変更により、プライベートなリポジトリに存在するマニフェストとクラスタの状態が同期されます。
Flux は、GitHub 以外のリポジトリの使用や通知機能の利用なども可能です。より詳しくは以下をご確認ください。
ワークロードのコストを管理する
Warning
ワークロードのコスト管理機能はプレビュー版です。予告なく仕様が変更される場合があるので利用には注意してください。
このページではワークロードのコストを管理する機能について説明します。
コストタグを設定する
Warning
コストタグを利用したコストの集計機能は後日追加予定です。
PFCP の Kubernetes クラスタに作成する Pod および PersistentVolumeClaim リソースには「コストタグ」と呼ばれるコスト管理のためのメタデータを設定できます。コストタグを設定することで、コストタグごとにクラスタの利用量を集計できます。
コストタグは次の名前の専用のラベルとしてリソースに設定します。ラベルには最大 16 文字の任意の文字列を設定できます。16 文字以上の文字列を設定した場合は先頭から 16 文字のみが記録されます。
cost.preferred.jp/tag
次の例では Pod および PersistentVolumeClaim リソースにコストタグを設定しています。
apiVersion: v1
kind: Pod
metadata:
name: jupyter-notebook
labels:
# コストタグの設定
cost.preferred.jp/tag: dev-research
spec:
# ...
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: jupyter-notebook-data
labels:
# コストタグの設定
cost.preferred.jp/tag: dev-research
spec:
# ...
デフォルトのコストタグをサブネームスペースに設定する
コストタグはリソースだけでなくサブネームスペースにも設定できます。サブネームスペースにコストタグを設定すると、そのサブネームスペース配下に作成された全ての Pod および PersistentVolumeClaim リソースの利用に対してコストタグの値が自動適用されます。サブネームスペースへのコストタグの設定は組織管理者の権限が必要です。
例えばサブネームスペース org-<組織名>--foo にコストタグを設定する場合は次のようにします。
$ kubectl edit subnamespaceanchor org-<組織名>--foo -n org-<組織名>
- spec: {}
+ spec:
+ labels:
+ - key: cost.preferred.jp/tag
+ value: dev
サブネームスペースにコストタグが設定された状態で Pod や PersistentVolumeClaim リソースにもコストタグを設定した場合は、リソースに設定したコストタグの値が採用されます。例えば次のようにコストタグが設定されていた場合は、Pod リソースのコストタグは dev-research として処理されます。
- サブネームスペースのコストタグの値:
dev - Pod リソースのコストタグの値:
dev-research
永続ストレージの種類と比較
PFCP では、データを永続的に保存するためのストレージとしてファイルストレージとブロックストレージを提供しています。 PFCP のファイルストレージは NFS(Network File System)、ブロックストレージは NVMe/TCP を通信プロトコルとしてストレージシステムと接続されています。
ファイルストレージ
PFCP のファイルストレージは複数の Pod から NFS プロトコルを利用してデータを共有できます。 組織内のワークロードから共通して参照されるデータを格納する場所、ログや処理した結果を保存する場所としての利用に適しています。
ブロックストレージ
PFCP のブロックストレージは NVMe/TCP を利用して Pod からストレージシステムに対するより高度な操作を可能にします。
ブロックストレージ上にファイルシステムを作成して扱うときは複数 Pod からのアクセスが実行できない代わりにより高速なアクセスが可能となります。 これは高い応答性能が求められるデータベースでの利用に適しています。
ブロックストレージ上にファイルシステムを作成せず raw device として扱うときはそのまま Linux のブロックデバイスとしての利用が可能となります。 これは既存のファイルシステムでは実現できない機能を実現したいときに利用されます。 デバイスレベルでの暗号化が求められる特殊なアプリケーションでの利用、専用のフォーマットを用いる仮想ディスクとしての利用などです。
比較
ここでは PFCP で提供しているストレージタイプにおいて利用可能なアクセスモードを示します。 表中のアクセスモードは以下に示す省略形で表記しています: ReadWriteOnce(RWO)、 ReadOnlyMany(ROX)、ReadWriteMany(RWX)、ReadWriteOncePod(RWOP)
| ストレージタイプ | RWO | ROX | RWX | RWOP | 備考 |
|---|---|---|---|---|---|
| ファイルストレージ | ◯ | ◯ | ◯ | ◯ | |
| ブロックストレージ | ◯ | ー | ー | ◯ | ファイルシステムを作成して扱うとき |
| ブロックストレージ | ◯ | ◯ | ◯ | ◯ | ファイルシステムを作成せず raw block device として扱うとき |
ファイルストレージを使用する
PFCP では、Pod からマウントして利用できるファイルストレージを提供しています。 ReadWriteMany のファイルストレージであり、組織内の複数の Pod から同時に読み書き可能です。
PersistentVolumeClaim の作成と Pod へのマウント
ファイルストレージを利用するには、PersistentVolumeClaim リソースを作成することで必要なストレージ領域を要求し、 動的に払い出された PersistentVolume を Pod からマウントします。その具体例を説明します。
-
組織ごとに用意された専用の StorageClass を指定して、PersistentVolumeClaim を作成します。利用可能な StorageClass 名は
standard-rwx-<組織名>です。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: hello-sample-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi storageClassName: standard-rwx-<組織名>この例では、10GiB のファイルストレージを要求する PersistentVolumeClaim を作成しています。 このマニフェストを Kubernetes に適用すると、動的に PersistentVolume が作成され、 以下の通り PersistentVolumeClaim のステータスが
Boundになることが確認できます。$ kubectl -n org-<組織名> get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE hello-sample-pvc Bound pvc-c5bb8161-f8f3-4b2d-b001-0aee300b7478 10Gi RWX standard-rwx-<組織名> <unset> 3d2h -
この PersistentVolumeClaim を指定して Pod にマウントすることで、ファイルストレージとして利用できます。
apiVersion: v1 kind: Pod metadata: name: jupyter-notebook spec: containers: - name: jupyter-notebook image: quay.io/jupyter/scipy-notebook:2024-03-14 volumeMounts: - mountPath: "/hello-sample" name: hello-sample-pv volumes: - name: hello-sample-pv persistentVolumeClaim: claimName: hello-sample-pvc
制限事項
すべてのファイル操作が nobody ユーザからのアクセスとして処理される
PFCP のファイルストレージではボリューム上のすべてのファイルとディレクトリに対する操作が nobody ユーザ(UID 65534、GID 65534)として処理されます。これはルートユーザ(UID 0)を含むすべての Linux ユーザで同様です。
Note
この制限事項はファイルストレージに対してのみ存在します。ブロックストレージには存在しません。
例として、下記では ubuntu ユーザ(UID 1000)がボリューム上にファイルを新規作成していますが、ファイル操作は nobody ユーザのアクセスとして処理されます。
そのため、作成されたファイルのオーナとグループが nobody:nogroup(65534:65534)となっていることを確認できます。
ubuntu@pv-test:~$ id
uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu)
ubuntu@pv-test:~$ ls -al /data-rwx
total 8
drwxrwxrwx 3 nobody nogroup 4096 Nov 10 23:28 .
drwxr-xr-x 1 root root 4096 Nov 10 23:09 ..
ubuntu@pv-test:~$ touch /data-rwx/testfile
ubuntu@pv-test:~$ ls -al /data-rwx/testfile
-rw-r--r-- 1 nobody nogroup 0 Nov 10 23:39 /data-rwx/testfile
ファイルのオーナが nobody である /data-rwx/testfile に対する更新操作の場合も nobody ユーザとして処理されるため権限エラーになることなく更新が成功します。
ubuntu@pv-test:~$ ls -al /data-rwx/testfile
-rw-rw-r-- 1 nobody nogroup 0 Nov 10 23:39 /data-rwx/testfile
ubuntu@pv-test:~$ date >/data-rwx/testfile
ubuntu@pv-test:~$ cat /data-rwx/testfile
Mon Nov 10 23:40:20 UTC 2025
ubuntu@pv-test:~$ ls -al /data-rwx/testfile
-rw-rw-r-- 1 nobody nogroup 29 Nov 10 23:40 /data-rwx/testfile
ただし、この制限からファイルストレージではボリューム上のファイルに対する chown/chgrp コマンドやボリュームのグループを Pod 実行時に変更する Pod securityContext fsGroup 等が機能しません。
chown/chgrp: Operation not permitted エラーが発生する
ファイルのオーナ・グループを変更する chown/chgrp コマンドをボリューム上のファイルに対して実行する場合は Operation not permitted エラーが発生して次のように失敗します。
root@pv-test:~# id
uid=0(root) gid=0(root) groups=0(root)
root@pv-test:~# chown root /data-rwx/testfile
chown: changing ownership of '/data-rwx/testfile': Operation not permitted
root@pv-test:~# chgrp root /data-rwx/testfile
chgrp: changing group of '/data-rwx/testfile': Operation not permitted
kubectl cp コマンドや tar/rsync コマンドを実行した際にも同様のエラーが発生します。これはコマンドが内部的にファイルやディレクトリのオーナを変更するためです。それぞれのコマンドでオーナを変更しないオプションを使用してエラーを回避できます。
kubectl cp:--no-preserveオプションtar:--no-same-ownerオプションrsync:--no-ownerオプション
Pod securityContext fsGroup: 設定が無視されて Pod が実行される
Pod 実行時にボリュームのグループを変更する Pod SecurityContext の fsGroup 機能はファイルストレージのボリュームに対しては設定が無視されて Pod が実行されます。
参考
ブロックストレージを使用する
PFCP では ReadWriteOnce、ReadWriteOncePod の PersistentVolume としてブロックストレージを利用できます。 ReadWriteOncePod のボリュームに対しては単一の Pod からのみアクセスが許可されます。
PersistentVolumeClaim にファイルシステムを作成して Pod へマウント
ブロックストレージにファイルシステムを作成して利用するには、PersistentVolumeClaim リソースを作成することで必要なストレージ領域を要求し、 動的に払い出された PersistentVolume を Pod からマウントします。 その具体例を説明します。
-
組織ごとに用意された専用の StorageClass を指定して、PersistentVolumeClaim を作成します。利用可能な StorageClass 名は
standard-rwo-<組織名>です。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: hello-sample-pvc spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: standard-rwo-<組織名> volumeMode: Filesystemこの例では、10GiB のブロックストレージにファイルシステムを作成して要求する PersistentVolumeClaim を作成しています。volumeMode はデフォルト値が Filesystem ですので実際にはここの指定は記述しなくても作成されるものは同じです。 このマニフェストを Kubernetes に適用すると、動的に PersistentVolume が作成され、 以下の通り PersistentVolumeClaim のステータスが
Boundになることが確認できます。$ kubectl -n org-<組織名> get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE hello-sample-pvc Bound pvc-ac98a6ff-58cd-4bef-8057-4837949107d0 10Gi RWO standard-rwo-<組織名> <unset> 7s -
この PersistentVolumeClaim を指定して Pod にマウントすることで、ファイルシステムとして利用できます。
apiVersion: v1 kind: Pod metadata: name: jupyter-notebook spec: containers: - name: jupyter-notebook image: quay.io/jupyter/scipy-notebook:2024-03-14 volumeMounts: - mountPath: "/hello-sample" name: hello-sample-pv volumes: - name: hello-sample-pv persistentVolumeClaim: claimName: hello-sample-pvc
PersistentVolumeClaim にファイルシステムを作成しないで Pod から使う
ブロックストレージを直接ブロックデバイスとして利用するには、PersistentVolumeClaim リソースを作成することで必要なストレージ領域を要求し、 Pod からはデバイスファイルを経由して動的に払い出された PersistentVolume を利用します。 その具体例を説明します。
-
組織ごとに用意された専用の StorageClass を指定して、PersistentVolumeClaim を作成します。利用可能な StorageClass 名は
standard-rwo-<組織名>です。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: hello-sample-pvc spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: standard-rwo-<組織名> volumeMode: Blockこの例では、10GiB のブロックストレージを生のブロックデバイスとして利用するための PersistentVolumeClaim を作成しています。volumeMode に Block と指定することでブロックストレージにファイルシステムを作成する操作が行われなくなります。 このマニフェストを Kubernetes に適用すると、動的に PersistentVolume が作成され、 以下の通り PersistentVolumeClaim のステータスが
Boundになることが確認できます。$ kubectl -n org-<組織名> get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE hello-sample-pvc Bound pvc-fb34c017-ce51-488c-a445-65981b031e0b 10Gi RWO standard-rwo-<組織名> <unset> 119s -
この PersistentVolumeClaim を指定して Pod のデバイスファイルとすることで、Pod からはブロックデバイスとして利用できます。
apiVersion: v1 kind: Pod metadata: name: block-demo spec: containers: - name: block-demo image: ubuntu command: - sleep - "3600" volumeDevices: - name: hello-sample-pv devicePath: /dev/block volumes: - name: hello-sample-pv persistentVolumeClaim: claimName: hello-sample-pvcここでは Pod の中からブロックデバイスとして操作できることの例を示します。 この例ではデバイスファイルは nvme2n1 にマッピングされ、PersistentVolumeClaim で指定した 10GiB の大きさを持つブロックデバイスとして認識されていることがわかります。
$ kubectl -n org-<組織名> exec -it block-demo -- bash root@block-demo:/# ls -lF /dev/block brw-rw---- 1 root disk 259, 20 Aug 9 03:49 /dev/block root@block-demo:/# lsblk /dev/block NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS nvme2n1 259:20 0 10G 0 disk root@block-demo:/#
参考
Namespace 間でファイルストレージを共有する
PFCP で提供されている 2 種類の永続ストレージのうち、 ファイルストレージについては組織内に作成された複数のネームスペースにまたがる複数の Pod から同時に読み書き可能です。
ファイルストレージの共有
Kubernetes における従来通りのファイルストレージは PersistentVolumeClaim リソース(以下 PVC)が作成されたネームスペースからのみ読み書きできるように アクセス範囲が制限されています。 PFCP では、同じ組織内のネームスペースであれば PVC が作成されたのとは異なるネームスペースからでも読み書きできるように ファイルストレージを共有する機能1が提供されています。
以下では、同じ組織内のネームスペースをまたいでファイルストレージを共有する方法を説明します。
ステップ 1. 共有元のネームスペースで PVC を作成する
説明のために例として作成する PVC の名前を pvc1 、
ファイルストレージを提供する側のネームスペースを org-example--namespace1 、
pvc1 の提供を受けて利用する側のネームスペースを org-example--namespace2 とします。
まず始めにファイルストレージを提供する側のネームスペースで共有したい PVC に trident.netapp.io/shareToNamespace アノテーションを付与します。
このアノテーションに設定されたネームスペースからの共有アクセスが認められるようになります。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
namespace: org-example--namespace1
annotations:
trident.netapp.io/shareToNamespace: org-example--namespace2
spec:
accessModes:
- ReadWriteMany
storageClassName: standard-rwx-example
resources:
requests:
storage: 100Gi
Tip
- PVCの共有先はカンマで区切ることで複数指定することができます。例:
trident.netapp.io/shareToNamespace: org-example--namespace2,org-example--namespace3,org-example--namespace4- アスタリスク
*を指定するとどのネームスペースからでもアクセスを許可することができます。例:trident.netapp.io/shareToNamespace: *- PVC の
trident.netapp.io/shareToNamespaceアノテーションはいつでも追加、変更できます2。
ステップ 2. 共有先のネームスペースで TridentVolumeReference を作成する
ファイルストレージが共有される先のネームスペースにおいてカスタムリソース TridentVolumeReference を作成します。 ここに記述する内容でどのネームスペースのどの PVC を参照しようとしているのかをシステムに通知します。
この説明の例ではネームスペース org-example--namespace2 からネームスペース org-example--namespace1 で共有設定がされている PVC pvc1 を参照したいので以下のような記述になります。
apiVersion: trident.netapp.io/v1
kind: TridentVolumeReference
metadata:
name: my-first-tvr
namespace: org-example--namespace2
spec:
pvcName: pvc1
pvcNamespace: org-exapmle--namespace1
ステップ 3. 共有先のネームスペースで PVC を作成する
ファイルストレージが共有される先のネームスペースにおいて PVC を作成します。
このとき trident.netapp.io/shareFromPVC アノテーションを付与することでどのネームスペースのどの PVC を利用するのかを指定します。
この説明の例ではネームスペース org-example--namespace1 にある PVC pvc1 を共有したいので以下のような記述になります。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
trident.netapp.io/shareFromPVC: org-example--namespace1/pvc1
name: pvc2
namespace: org-example--namespace2
spec:
accessModes:
- ReadWriteMany
storageClassName: standard-rwx-example
resources:
requests:
storage: 100Gi
Note
共有先の PVC で指定するストレージのサイズに共有元の PVC のサイズを超える値を指定することはできません。
ステップ 4. 通常の PVC と同じように利用する
通常の PVC と同様にして Pod にマウントしてファイルストレージとして利用します。
Warning
共有先の PVC がクオータを消費してしまう
共有先のPVCは、通常のPVCと同様に
resource.requests.storageが割り当てられた扱いとなります。つまり、組織内のネームスペースに ResourceQuota が設定されていた場合は、それを消費して作成したことになります。共有先のPVCの要求値は共有元のPVCの設定値と異なる値を設定できるため、resource.requests.quotaを1(1バイト)などなるべく小さな値に設定することで、ResourceQuotaの消費量を最小限に抑えることができます。ただし、共有元のPVCの要求値を越える値を要求することはできません。
共有ファイルストレージの削除
複数のネームスペースで共有されているファイルストレージであっても削除の順番に特別な注意を払う必要はありません。 必要のなくなったネームスペースから PVC を通常の方法で削除してください。 どのネームスペースからも共有ファイルストレージが参照されていないことを検知するとシステムによってボリュームが削除されます。
参考リンク
-
Astra Trident の TridentVolumeReference を採用しています。 ↩
-
実際に共有アクセスが可能かどうかを評価するのは後述する共有する側の PVC を作成するタイミングになります。 ↩
永続ストレージのスナップショット
永続ストレージのスナップショットは、データのバックアップや復元を簡単に行うための機能です。 特定の時点でのボリュームのコピーを作成でき、ボリュームを以前の状態に戻すことや、新しいボリュームを作成できます。 一度作成したスナップショットは、元となったボリュームが更新されても状態が変わりません。 そのため、バックアップやバージョニング等の用途に利用できます。
このドキュメントでは、スナップショットの作成、管理、および使用方法について説明します。
ボリュームからスナップショットを作成する
既存のボリュームを元に、現時点の状態のスナップショットを作成します。
ここでは、以下のような PersistentVolumeClaim(PVC)があるとします。この PVC hello-sample-pvc に対して、スナップショットを作成したいとします。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: hello-sample-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Mi
storageClassName: standard-rwo-<組織名>
volumeMode: Filesystem
- スナップショットを作成する PVC の名前を指定した VolumeSnapshot リソースのマニフェストを作成します。
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: hello-snapshot-v1
spec:
source:
persistentVolumeClaimName: hello-sample-pvc
このマニフェストを Kubernetes に適用することで、その瞬間のボリュームの状態が保存され、新規スナップショットが作成されます。
- スナップショットが正常に作成されたかどうかは、
kubectl get volumesnapshotsで確認できます。
$ kubectl get volumesnapshots
NAME READYTOUSE SOURCEPVC SOURCESNAPSHOTCONTENT RESTORESIZE SNAPSHOTCLASS SNAPSHOTCONTENT CREATIONTIME AGE
hello-snapshot-v1 true hello-sample-pvc ...Mi trident snapcontent-.......... ..d ..d
正常なスナップショットは READYTOUSE の項目が true となります。この場合 PersistentVolumeClaim からのスナップショットが成功しています。
Note
READYTOUSEがtrueでない場合はまだ作成が完了していません。データをコピーするため、スナップショットの作成には数秒 〜1 分程度かかることがあります。
スナップショットからボリュームを復元する
以下のように PVC のマニフェストを書くことで、スナップショットから新たなボリュームを作成できます。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: hello-sample-pvc-restored
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 20Mi
storageClassName: standard-rwo-<組織名>
dataSource:
name: hello-snapshot-v1
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
計算ノードの種類と比較
PFCP では、 2 種類の計算ノードが利用可能です。
- 専有ノード (Reserved Node): 組織に対して専有の計算ノードです。
- 共有ノード (Shared Node): 複数の組織で共有される計算ノードです。
以下は各種類の計算ノードの各機能のサポート状況です。
| 機能 | 専有ノード | 共有ノード |
|---|---|---|
| 費用 | 月額 | 従量課金 |
| 拡張リソース (MN-Core 2 等) を要求していない Pod の作成 | ◯ | × |
| Pod の CPU/Memory 等のリソース要求量制限 | なし | あり |
| RWX の永続ストレージ | ○ | ○ |
| RWO の永続ストレージ | ○ | ○ |
| サブネームスペースでのリソースクオータ | ○ | ○ |
| モニタリング | ○ | ○ |
専有ノードを使用する
専有ノードは、組織のワークロードで専有できる計算ノードの種類です。
組織内の Namespace に作成された Pod は組織間のワークロードで共有される計算ノードである共有ノードでの実行を明示的に指定しない限り専有ノードにスケジュールされるため、利用者自身によるノード選択(nodeSelector の記述)は不要です。
組織に割り当てられた専有ノードは ReservedNode というリソースを通じて参照できます。次のコマンド例では組織に割り当てられた全ての専有ノードを出力します。
kubectl get reservednodes
ReservedNode リソースは Kubernetes の Node リソースと同様に扱うことができ、Label Selector や Field Selector による選択ができます。Field Selector がサポートするフィールドは次の通りです。
metadata.namespec.unschedulable
なお、ReservedNode リソースは読み取り専用であるため、リソースの変更はできません。
Warning
メンテナンス時のワークロードへの影響
計算ノードの再起動を伴うメンテナンスにおいて専有ノードの一部が一時的に使用できなくなる可能性があることに注意してください。
- 専有ノードの契約台数が 4 台未満の場合は 1 台ずつ、4 台以上の場合は最大 25%(小数切り捨て)が一時的に使用できなくなります
- 1 台のみ契約されている場合は一時的に利用できるノードがなくなります
メンテナンス時のワークロードに対する影響についてはメンテナンスポリシを参照ください。
共有ノードを使用する
Warning
本機能は現状では SR1 のみでの提供となっています。 また、提供される共有ノードの数には上限があり、利用状況によっては利用できない可能性があります。 共有ノードの利用状況の可視化は今後の提供を予定しています。
PFCP では、複数の組織で共有されるノードを提供しています。共有ノードは、組織に割り当てられた専有ノードとは異なり複数の組織で共有されます。
利用できるノード
以下を共有ノードとして提供しています。
- MN-Server 2(
preferred.jp/mncore2)
利用方法
Pod に専用の PriorityClass を指定することで、自動的に共有ノードにスケジューリングされます。PriorityClass は Pod の優先度を指定するための機能ですが、ここではどのタイプのノードに Pod をスケジューリングするかの制御にも利用されます。
そのため、利用者自身によるノード選択(nodeSelector の記述)は不要です。
以下は Pod を共有ノードで利用する例です。
apiVersion: v1
kind: Pod
metadata:
name: shared
spec:
priorityClassName: shared-standard # or shared-best-effort
...(省略)...
共有ノードを使用するための PriorityClass は以下の通りです。
shared-standard: 共有ノード用の PriorityClass のなかでもっとも優先度が高くプリエンプトされない(追い出されない)shared-best-effort:shared-standardPriorityClass の Pod にプリエンプトされる
Pod の優先度とプリエンプションの詳細は Kubernetes 公式ドキュメントを参照ください。
共有ノードで各組織が利用できる MN-Core 2 の数は PriorityClass それぞれで上限が設定されています。以下のコマンドで利用可能な MN-Core 2 の数を確認できます。
kubectl -n org-<組織名> get hrq shared-standard shared-best-effort -o yaml
制約事項
- 1 つの MN-Core 2 で要求できる最大リソース量には制限があります。1 Pod で 2 つの MN-Core 2 を要求する場合では上限値は 2 倍になります。各リソースの 1 つの MN-Core 2 あたりの上限値は以下の通りです。
リソース 1つの MN-Core 2 あたりの上限値 CPU 7000m Memory 125Gi Ephemeral Storage 80Gi
セキュリティ
共有ノードは専有ノードとは異なり、複数の組織のワークロードが同じノード上でカーネルを共有します。 組織間のセキュリティ境界についてより強固な分離が必要な場合は、専有ノードの利用を推奨します。
追加のセキュリティ対策
共有ノードでは Linux の User Namespaces を用いて、ホストから Pod 内のコンテナの UID/GID を強制的に分離します。 この技術を用いることで脆弱性等によりコンテナからホストに侵入された場合でも、ホスト内の root ユーザ、つまり UID が 0 のユーザとしてホストを操作できないため、リスクが低減されます。 Linux の User Namespaces は過去の多くのコンテナに関する CVE を防ぐことが知られています1。 詳細は Kubernetes 公式の User Namespaces のドキュメントをご参照ください。
-
https://github.com/kubernetes/enhancements/tree/217d790720c5aef09b8bd4d6ca96284a0affe6c2/keps/sig-node/127-user-namespaces#motivation ↩
ユーザ管理のコンテナイメージを使用する
Note
このページでは、ユーザ自身が管理するコンテナイメージレジストリに保存されているコンテナイメージを使用するための手順を説明します。 PFCP が提供するコンテナイメージの使用については、PFCP 提供のコンテナイメージについて をご参照ください。
PFCP では Amazon ECR および Google Artifact Registry のプライペートレジストリに保存されているコンテナイメージの取得をサポートしています。 Image pull secrets provisionerというシステムがデプロイされており、 これを使うことで ECR や Google Artifact Registry からイメージを取得するための Secret を自動作成・更新できます。
ECRのコンテナイメージを使用したワークロードの起動
-
AWS 側で、使用する Kubernetes ServiceAccount に対する ID 連携を構成します。
- この Kubernetes ServiceAccount を使う Pod が、ECR からイメージを取得できるように信頼関係を構成します。
- 構成方法については、AWS ドキュメント Create an OpenID Connect (OIDC) identity provider in IAM - AWS Identity and Access Management をご確認ください。
- プロバイダ(発行者)URL は 拠点と計算ノード を参照してください。1
- AWS のマニフェスト管理に Terraform をご利用であれば、Terraform 設定の例 も参照ください。
-
使用する ServiceAccount に、以下のアノテーションを付与します。
apiVersion: v1 kind: ServiceAccount metadata: namespace: NAMESPACE name: SERVICE-ACCOUNT-NAME annotations: # 使用したいコンテナイメージが格納されているECRレジストリを指定します。 imagepullsecrets.preferred.jp/registry: 999999999999.dkr.ecr.LOCATION.amazonaws.com # ID連携を用いたECRアクセスにおいて使用されるaud値を指定します。 imagepullsecrets.preferred.jp/audience: sts.amazonaws.com # ECRアクセスの際に、AssumeRoleにより使用されるIAM Roleを指定します。 imagepullsecrets.preferred.jp/aws-role-arn: arn:aws:iam::999999999999:role/ROLE-NAME -
Pod の
.spec.serviceAccountNameフィールドを指定することで、Pod がこの ServiceAccount を使うように設定します。apiVersion: v1 kind: Pod metadata: name: POD-NAME spec: serviceAccountName: SERVICE-ACCOUNT-NAME ... -
Pod を起動し、ECR からイメージ取得できることを確認します。
Google Artifact Registryのコンテナイメージを使用したワークロードの起動
-
Google Cloud 側で、使用する Kubernetes ServiceAccount に対する ID 連携を構成します。
- この Kubernetes ServiceAccount を使う Pod が、Google Artifact Registry からイメージを取得できるように信頼関係を構成します。
- 構成方法については、Google Cloud ドキュメント Configure workload identity federation with Kubernetes | IAM Documentation | Google Cloud をご確認ください。
- プロバイダ(発行者)URL は 拠点と計算ノード を参照してください。1
- Google Cloud のマニフェスト管理に Terraform をご利用であれば、Terraform 設定の例 も参照ください。
-
使用する ServiceAccount に、以下のアノテーションを付与します。
apiVersion: v1 kind: ServiceAccount metadata: namespace: NAMESPACE name: SERVICE-ACCOUNT-NAME annotations: # 使用したいコンテナイメージが格納されているGoogle Artifact Registryのレジストリを指定します。 imagepullsecrets.preferred.jp/registry: LOCATION-docker.pkg.dev # ID連携を用いたGoogle Artifact Registryアクセスにおいて使用されるaud値を指定します。 imagepullsecrets.preferred.jp/audience: //iam.googleapis.com/projects/999999999999/locations/global/workloadIdentityPools/POOL-NAME/providers/PROVIDER-NAME # ID連携に使うWorkload Identityプロバイダのリソース名を指定します。 imagepullsecrets.preferred.jp/googlecloud-workload-identity-provider: projects/999999999999/locations/global/workloadIdentityPools/POOL-NAME/providers/PROVIDER-NAME # ID連携に使うGoogleサービスアカウントのEメールアドレスを指定します。 imagepullsecrets.preferred.jp/googlecloud-service-account-email: SERVICE-ACCOUNT-ID@PROJECT-NAME.iam.gserviceaccount.com -
Pod の
.spec.serviceAccountNameフィールドを指定することで、Pod がこの ServiceAccount を使うように設定します。apiVersion: v1 kind: Pod metadata: name: POD-NAME spec: serviceAccountName: SERVICE-ACCOUNT-NAME ... -
Pod を起動し、Google Artifact Registry からイメージ取得できることを確認します。
より詳細については image pull secrets provisioner の README をご確認ください。
PFCP 提供のコンテナイメージを使用する
このページでは、PFCP サービスの一部としてお客様に提供するコンテナイメージを使用するための手順を説明します。 お客様が管理するコンテナイメージの使用については、お客様管理のコンテナイメージについて をご参照ください。
Warning
PFCP 提供のコンテナイメージは、PFCP の Kubernetes クラスタ内からのみ利用できます。 それ以外の環境ではイメージの取得に失敗します。
PFCP 提供のコンテナイメージ一覧
PFCP が提供するコンテナイメージの一覧は、ポータルの イメージ ページで確認できます。
PFCP 提供のコンテナイメージを使用したワークロードの起動
以下の手順で、PFCP 提供のコンテナイメージを使用したワークロードを起動します。
- Pod の
spec.containers.imageフィールドに、使用したいコンテナイメージを指定します。apiVersion: v1 kind: Pod metadata: name: POD-NAME spec: containers: - name: CONTAINER-NAME image: registry.pfcomputing.internal/IMAGE:TAG ... - Pod を起動し、コンテナイメージを取得できることを確認します。
インタラクティブな作業環境を作成する
インタラクティブな作業環境をクラスタ上に作成するにはワークスペース機能を使用します。 ワークスペースは、ブラウザからアクセスできるインタラクティブな作業環境です。 JupyterLab などのインターフェイスを通して PFCP の計算リソースを利用できます。
ワークスペースの隔離
ワークスペースの各インスタンスを隔離する単位は、個人ユーザ と ネームスペース の 2 通りがあります。 ワークスペースを作成する際に、どちらかの隔離タイプを選んで作成できます。
個人ユーザ
個人ユーザ単位で隔離するワークスペースは、ワークスペースを作成したユーザのみが利用できます。 そのため、SSH 秘密鍵など個人の認証情報を安全に保存できます。
組織管理者を含め、他のユーザは利用できません。 ただし、組織管理者はワークスペースを休止・削除できます。
利用可能な操作を以下に一覧します。
| 操作 | ワークスペースを作成したユーザ | 組織管理者 | その他のユーザ |
|---|---|---|---|
| ブラウザからワークスペースへのアクセス | o | ||
| ワークスペースの更新 | o | ||
| 稼働中のワークスペースの休止 | o | o | |
| 休止中のワークスペースの再開 | o | ||
| ワークスペースの削除 | o | o |
ネームスペース
ネームスペース単位で隔離するワークスペースは、ワークスペースが作成されたネームスペースに対し org-edit Role をもつユーザが利用できます。
そのため、ネームスペースに対する権限をもつユーザ間でワークスペースを共有できます。
ネームスペースに対し org-edit Role をもたないユーザは利用できません。
ワークスペースを作成する
Note
ワークスペースは、お使いの組織の計算リソースを利用します。 計算リソースが不足している場合、ワークスペースの作成に失敗することがあります。
Note
個人ユーザ単位で隔離するワークスペースは、ルートネームスペースにのみ作成可能です。 そのため、作成にはルートネームスペースに対する
org-editまたはorg-workspace-editClusterRole の付与が必要です。 ClusterRole を付与する方法は、RoleBinding の作成 をご参照ください。
- ポータルの ワークスペースページ にアクセスし、新規作成 ボタンをクリックします。
- フォームを入力し、作成 ボタンをクリックします。
ワークスペースにアクセスする
- ポータルの ワークスペースページ にアクセスします。
- アクセスしたいワークスペースの URL 列にあるリンクをクリックします。
ワークスペースを休止・再開する
Warning
ワークスペースを休止すると、ワークスペース内のデータが削除されます。 PersistentVolume に保存されているデータは、休止中も保持されます。
利用していないワークスペースを休止することで、計算リソースを節約できます。
- ポータルの ワークスペースページ にアクセスします。
- 休止したいワークスペースを選択し、休止 ボタンをクリックします。
休止したワークスペースは、同様の手順で再開できます。
- ポータルの ワークスペースページ にアクセスします。
- 再開したいワークスペースを選択し、再開 ボタンをクリックします。
ワークスペースを削除する
Warning
ワークスペースを削除すると、ワークスペース内のデータ、およびワークスペースから作成した PersistentVolume がすべて削除されます。
- ポータルの ワークスペースページ にアクセスします。
- 削除したいワークスペースを選択し、削除 ボタンをクリックします。
Kubernetes マニフェストでワークスペースを管理する
ワークスペースはポータルでの操作のほかに、Kubernetes マニフェストを使った管理も可能です。 マニフェストを使うことで、ワークスペースの管理を自動化でき、ワークスペース設定の再現性を高めることができます。
Workspace カスタムリソース
ワークスペースの各インスタンスは、Workspace カスタムリソースで表現されます。
Workspace リソースから、ワークスペースの実体となる Pod が作成されます。 Workspace リソースを作成・更新・削除することで、ワークスペースを管理できます。
Workspace リソースは以下の形式で定義されます。
apiVersion: preferred.jp/v1alpha1
kind: Workspace
metadata:
name: ...
namespace: ...
spec:
owner:
type: Individual
presetRef: ...
podTemplate: ...
volumeClaimTemplates:
- ...
Tip
kubectl explain workspaceコマンドでも各フィールドの説明を確認できます。
spec.owner.typeフィールド- ワークスペースの隔離タイプを指定します。
- 個人ユーザで隔離する場合は
Individual、ネームスペースで隔離する場合はNamespaceを指定します。
spec.presetRefフィールド- ワークスペースに適用する プリセット を指定します。
spec.podTemplateフィールド- ワークスペースの実体となる Pod に適用する PodTemplateSpec を指定します。
spec.volumeClaimTemplatesフィールド- ワークスペースから作成する PersistentVolumeClaim のリストを指定します。
- 作成する PersistentVolumeClaim を
spec.podTemplateで参照することで、ワークスペースから PersistentVolume を利用できます。
プリセット
ワークスペースの実体となる Pod の構成を プリセット として事前に定義できます。 プリセットを定義することで、似た構成をもつワークスペースの管理を簡素化できます。
プリセットは、ワークスペースに適用する spec.podTemplate フィールドのデフォルト値を定義します。
Workspace リソースからワークスペースの実体となる Pod が作成される際、Workspace リソースの spec.podTemplate フィールドに記述しなかったフィールドはプリセットから引き継がれます。
spec.podTemplate フィールドに記述したフィールドは、その値で上書きされ Pod が作成されます。
プリセットには、ClusterWorkspacePreset カスタムリソースと WorkspacePreset カスタムリソースの 2 種類があります。
ClusterWorkspacePreset カスタムリソース
ClusterWorkspacePreset カスタムリソースは、PFCP マネージドなクラスタ全体で共有されるプリセットです。 すべての組織のワークスペースで利用できます。
利用可能な ClusterWorkspacePreset リソースは、kubectl get clusterworkspacepreset コマンド(または kubectl get cwspreset)で確認できます。
Workspace リソースの spec.presetRef フィールドを以下のように設定することで、適用したい ClusterWorkspacePreset を選択できます。
apiVersion: preferred.jp/v1alpha1
kind: Workspace
spec:
presetRef:
apiVersion: preferred.jp/v1alpha1
kind: ClusterWorkspacePreset
name: NAME
spec.presetRef フィールドを省略した場合、default ClusterWorkspacePreset が適用されます。
default ClusterWorkspacePreset の一部の値を抜粋すると、以下のようになっています。
apiVersion: preferred.jp/v1alpha1
kind: ClusterWorkspacePreset
metadata:
name: default
spec:
podTemplate:
spec:
containers:
- name: workspace
image: registry.pfcomputing.internal/mncore-sdk/mncore-sdk-full
command:
- /app/jupyter/bin/jupyter
- lab
Workspace リソースの spec.podTemplate フィールドを記述しなかった場合、この値に従い、MN-Core SDK のコンテナイメージで JupyterLab を起動する workspace コンテナをもつ Pod が作成されます。
spec.podTemplate フィールドでコンテナイメージやコマンドなどを指定することで、このデフォルト設定を上書きできます。
また、workspace コンテナのリソース要求の設定や、workspace 以外のコンテナの追加も可能です。
WorkspacePreset カスタムリソース
WorkspacePreset カスタムリソースは、ネームスペース単位で共有されるプリセットです。
ネームスペースに対する org-edit Role をもつユーザが作成・更新・削除できます。
ネームスペースに存在する WorkspacePreset リソースは、kubectl get workspacepreset コマンド(または kubectl get wspreset)で確認できます。
Workspace リソースの spec.presetRef フィールドを以下のように設定することで、適用したい WorkspacePreset を選択できます。
apiVersion: preferred.jp/v1alpha1
kind: Workspace
spec:
presetRef:
apiVersion: preferred.jp/v1alpha1
kind: WorkspacePreset
name: NAME
Note
Workspace が WorkspacePreset を参照するには、Workspace と WorkspacePreset が同じネームスペースに存在する必要があります。
作業環境に Visual Studio Code で接続する
ワークスペース機能で作成した作業環境に、Visual Studio Code(VSCode) から接続できます。 お手もとで設定済みの VSCode 環境を利用し、コードの編集やデバッグをおこなえます。
トンネルを通して接続する
この方法では、VSCode の Remote Tunnels 機能を使用して、ワークスペースに接続します。
Note
この方法を利用するには、Visual Studio Code Server License Terms と Microsoft Privacy Statement への同意が必要です。
Warning
この方法は PFCP の認証・認可が適用されない経路でワークスペースに接続します。 そのため、PFCP と認証基盤を連携していても、その認証基盤を経由しない方法でのサービス利用となることに注意してください。 また、Remote Tunnels の機能を利用するユーザの管理・停止は PFCP と連携されておらず、ユーザ自身でおこなう必要があります。
ワークスペースでの準備
- ワークスペースを作成します。
- ワークスペースを作成する を参照してください。
- JupyterLab のターミナルを開き、以下のコマンドを実行してトンネルを開始します。
- ワークスペースで使われるデフォルトのコンテナイメージには
codeコマンドが含まれています。他のイメージを使う場合、codeコマンドがインストールされていることを確認してください。
code tunnel - ワークスペースで使われるデフォルトのコンテナイメージには
- コマンドが出力する指示にしたがって、初期設定を完了します。
VSCode からの接続
- お手もとの VSCode を起動します。
- 未インストールの場合、Remote - Tunnels 拡張機能 をインストールします。
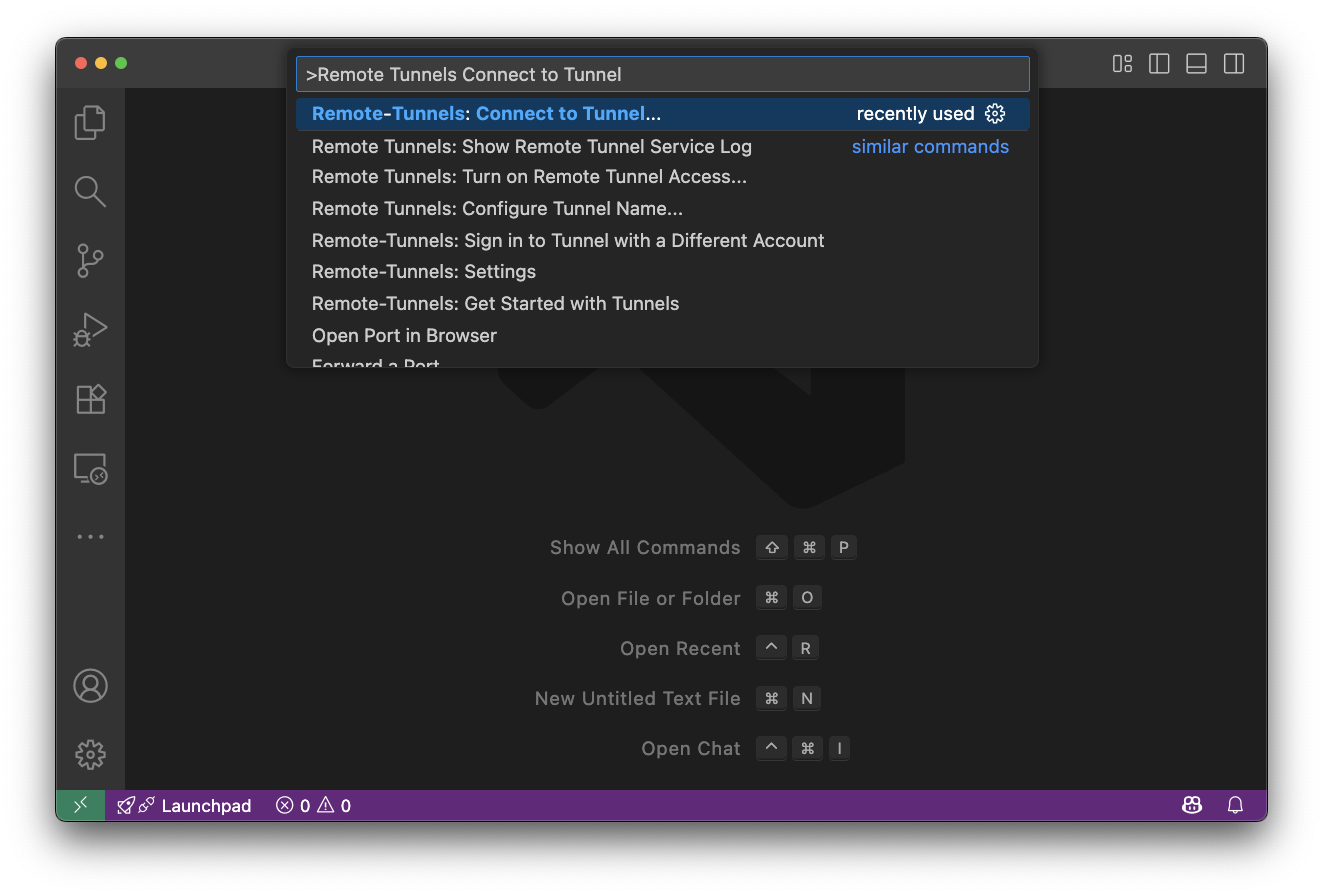
- コマンドパレットから Remote-Tunnels: Connect to Tunnel… を選択して接続を開始します。
- 指示にしたがって認証を完了し、ワークスペースに接続します。
分散バッチジョブを作成する
このページでは PFCP クラスタ上で分散バッチ処理を実行するための ParallelJob の作成方法を説明します。
Note
実験的機能のため、将来 API スキーマが変更される可能性があります。
概要
ParallelJob は、複数のノード間で協調して動作する分散バッチジョブを簡単にデプロイ・管理するための Kubernetes カスタムリソースです。ParallelJob には以下の特徴があります。
- 複数のフレームワークに対応: MPI などの分散処理フレームワークをサポート。
- Gang Scheduling: 分散バッチジョブ内の全 Pod が同時にスケジューリングされることを保証。
- ジョブ失敗時の再実行: 1 つのジョブが失敗した場合の ParallelJob 全体の自動再実行。
ParallelJob がサポートしているランタイム
Note
今後、複数のランタイムをサポートする予定ですが、現時点では Open MPI ランタイムのみ利用可能です。
Open MPI
Message Passing Interface(MPI)実装の 1 つである Open MPI を使用した並列計算をサポートします。Open MPI ジョブでは、1 つの launcher Pod が複数の worker Pod に SSH 経由で接続し、MPI を用いた並列計算を実行します。launcher Pod は rank=0 の worker としても使用されます。
以下は、MPI ランタイムを使用する ParallelJob の設定例です。
apiVersion: preferred.jp/v1alpha1
kind: ParallelJob
metadata:
name: mpi-sample-job
spec:
# 利用するMPIランタイムを指定
runtimeRef:
name: mpi-openmpi
# LauncherとWorkerを含むPodの数です。
# MPIランタイムではLauncherは1つで、残りがWorkerとなります。
numPods: 3
# PodあたりのMPIプロセス数で、MPIのhostfileのslotsに設定されます。
# アクセラレータを用いた計算の場合は Pod あたりの アクセラレータ数、flat MPI の場合は CPU コア 数、ハイブリッド並列の場合は 1 を指定するケースが多いです。
numProcPerPod: 2
# Launcher用PodのTemplateの設定です。PodTemplateSpec形式で記述します。
# `main` コンテナが含まれない場合、ParallelJobの作成に失敗します。
launcher:
spec:
containers:
- name: main # MPIを実行するコンテナは `main` としてください。
image: ghcr.io/pfnet/parallel-controller/openmpi:v0.1.0
command:
- sh
- -c
- |
mpirun --allow-run-as-root sh -c '
cat > hello_mpi.c << "EOF"
#include <mpi.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
MPI_Init(&argc, &argv);
int rank, world_size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
printf("Hello from MPI process %d rank in %d processes\n", rank, world_size);
MPI_Finalize();
return 0;
}
EOF
mpicc -o hello_mpi hello_mpi.c
./hello_mpi'
# (Optional) Worker用PodのTemplateの設定です。PodTemplateSpec形式で記述します。
# Workerの設定はLauncherから継承され、Launcherと通信する用のコンテナは `main` という名前で自動生成されます。
# worker: nil
Note
独自のコンテナイメージを使用する
Open MPI ランタイムで独自のコンテナイメージを使用する場合は下記のソフトウェアが含まれている必要があります。
- Open MPI
- ssh (SSH クライアント)
- sshd (SSH サーバー)
シーン別設定例
以下に、実際の利用シーンでよく使用される設定例を示します。
失敗時のリトライ設定
デフォルトでは、ParallelJob 内のいずれかのジョブが失敗した場合、ParallelJob 全体が最大 3 回まで再実行されます。リトライ回数を変更するには、.spec.failurePolicy.maxRestarts フィールドを設定します。以下は、リトライ回数を 1 回に設定する例です。
apiVersion: preferred.jp/v1alpha1
kind: ParallelJob
metadata:
name: mpi-sample-job
spec:
failurePolicy:
# ジョブ失敗時にParallelJob全体を再実行する最大回数です。(デフォルト: 3)
maxRestarts: 1
...
Note
Preemption や Eviction によるジョブ中断はリトライ回数にカウントされません。
GPU/RDMAリソースの指定
分散ジョブで GPU や RDMA リソースを使用する場合、Pod テンプレートで該当リソース要求を指定します。 NCCL や UCX の設定ファイルは自動生成されますが、読み込みは明示的に行う必要があります。以下は、launcher Pod に GPU と RDMA デバイスを要求し、NCCL と UCX の設定ファイルを読み込む例です(今後のアップデートで自動化予定です)。
apiVersion: preferred.jp/v1alpha1
kind: ParallelJob
metadata:
name: sample-job
spec:
launcher:
spec:
containers:
- name: main
command: ["/bin/sh", "-c"]
args:
# Note: NCCLやUCX用の設定ファイルは自動生成されますが、読み込みは明示的に行う必要があります。
- |
[ -f "$RDMA_NCCL_CONF" ] && . "$RDMA_NCCL_CONF"
[ -f "$RDMA_UCX_CONF" ] && . "$RDMA_UCX_CONF"
mpirun --allow-run-as-root something-using-gpu-rdma
resources:
limits:
nvidia.com/gpu: "2"
preferred.jp/rdma: "1"
...
Note
RDMA リソースは次のクラスタでのみ利用可能です。
- IK1-01
- YH1-01
トラブルシューティング
分散ジョブの実行中に問題が発生した場合、以下の手順でトラブルシューティングを行います。
ジョブの状態確認
ParallelJob の状態を確認するには、以下のコマンドを実行します。
# ParallelJob の状態を確認
kubectl get paralleljobs sample-job
# イベントを含めた詳細情報を確認
kubectl describe paralleljobs sample-job
関連する Job / Pod の状態を確認するには、以下のコマンドを実行します。
# ParallelJob に紐づく JobSet 名を変数に設定
jobset_name=$(kubectl get paralleljobs sample-job -o jsonpath={".status.jobGroupName"})
# 関連する Job / Pod の状態を確認
kubectl get jobs,pods -l jobset.sigs.k8s.io/jobset-name=${jobset_name}
Podのログ確認
rank=0 の Pod のログを取得するには、以下のコマンドを実行します。
# ParallelJob に紐づく JobSet 名を変数に設定
jobset_name=$(kubectl get paralleljobs sample-job -o jsonpath={".status.jobGroupName"})
# ログの表示
kubectl logs -f $(kubectl get pod -l jobset.sigs.k8s.io/jobset-name=${jobset_name},jobset.sigs.k8s.io/job-global-index=0 -o name)
Note
ログは、Pod が存在する場合のみ確認できます。正常終了の場合はすべての Pod が残り、エラー終了の場合はエラーとなった Pod のみが残ります。また、ParallelJob を削除すると、関連する Pod もすべて削除されます。
ワークロードをウェブアプリとして公開する
PFCP の WebApp Identity-Aware Proxy(WebApp IAP)機能を使うことで、ワークロードをウェブアプリとしてインターネットに公開できます。 公開するウェブアプリには自動でアクセス時の認証が設定され、同一組織に属するユーザのみブラウザからアクセスできます。
WebApp IAP を利用してウェブアプリをインターネットに公開する方法を説明します。
Note
CLI などからアクセスする ウェブ API としてワークロードを公開したい場合は ワークロードをウェブ API として公開する を参照してください。
ウェブアプリを組織全体に公開する
-
公開するワークロードと Service リソースを用意します。ここでは例として、
example-svcService の 80 番ポートへアクセスすることでワークロードへアクセスできる状態になっているとします。 -
以下を参考に、Ingress マニフェストを作成します。
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: example-ingress spec: rules: - # Ingress に割り当てるドメインを指定します。 # 注意: ウェブ API での公開と異なり、`ingress.pfcomputing.com` のサブドメインを指定します。 host: example.<組織名>.<クラスタ名>.ingress.pfcomputing.com http: paths: - path: / pathType: Prefix backend: # 公開対象の Service 名とポートを指定します。 service: name: example-svc port: number: 80Warning
サブドメインの制限
ウェブアプリ用 Ingress ではドメインとして
*.<組織名>.<クラスタ名>.ingress.pfcomputing.comのみ使用できます。例えば、組織名が
fooでクラスタ名がsr1-01の場合は*.foo.sr1-01.ingress.pfcomputing.comとなります。 -
ポータルのパブリックエンドポイント にアクセスし、 クラスタ名 と ネームスペース名 を選択します。出力されるパブリックエンドポイント一覧の中に、作成した Ingress のサブドメインが含まれることを確認します。
-
指定したサブドメインにブラウザからアクセスし、ログインした後1、公開したサービスにアクセスできることを確認します。
ウェブアプリを組織の一部ユーザに限定公開する
ウェブアプリの公開範囲を、組織内の特定のユーザもしくはユーザグループに限定できます。
まずは「ウェブアプリを組織全体に公開する」の手順に従って Ingress を作成してください。 その後、公開範囲を制限したい Ingress に対して、以下のようにアノテーションを追加してください。 値には、アクセスを許可するユーザのメールアドレスまたはユーザグループの名前をカンマ区切りで記載してください。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
annotations:
# 特定のユーザを許可する場合は allowed-users アノテーションを追加する
ingress.preferred.jp/allowed-users: "foo@example.com, bar@example.com, baz@example.com"
...
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
annotations:
# 特定のユーザグループを許可する場合は allowed-groups アノテーションを追加する
ingress.preferred.jp/allowed-groups: "foo-group, bar-group"
...
両方のアノテーションを追加したときは、指定されたユーザおよびユーザグループの両方に対してアクセスが許可されます。
ユーザグループの管理については 組織のユーザを管理する を参照してください。
Tip
自身が所属するユーザグループは
kubectl auth whoamiコマンドでも確認できます。組織fooのユーザグループbarに所属している場合、Groupsのリストにoidc:org-foo/barという値が入ります。
公開範囲を制限できているか確認する
アノテーションを付与したあとは、実際に Ingress へアクセスして公開範囲を制限できているか確認してください。
Warning
ユーザグループの変更操作が、既存のログイン済みユーザのセッションに反映されるまで、時間がかかることがあります。 再ログインやブラウザクッキーの消去を試してください。
公開範囲を制限すると、Ingress に nginx.ingress.kubernetes.io/auth-url アノテーションが追加されます。
このアノテーションが追加されていない場合は、アノテーションの typo などがないかマニフェストを確認してください。
公開範囲を組織全体へ戻す
Ingress に付与されている以下のすべてのアノテーションを削除してください。
ingress.preferred.jp/allowed-usersingress.preferred.jp/allowed-groupsnginx.ingress.kubernetes.io/auth-url
制限事項
- Service リソースの
NodePort、LoadBalancer、ExternalNameタイプを使用したサービスの公開をサポートしていません - リクエストボディのサイズ上限は 10MB です
-
ブラウザに有効な認証キャッシュが存在する場合、ログイン処理はスキップされます。 ↩
ワークロードをウェブ API として公開する
PFCP の API Identity-Aware Proxy(API IAP)機能を使うことで、ワークロードをウェブ API としてインターネットに公開できます。 公開するウェブ API には自動でアクセス時の認証が設定され、アクセスには Kubernetes ServiceAccount のトークンが必要になります。
API IAP を利用してウェブ API をインターネットに公開する方法を説明します。
Note
ブラウザからアクセスする ウェブアプリ としてワークロードを公開したい場合は ワークロードをウェブアプリとして公開する を参照してください。
サポートするプロトコル
次のプロトコルによる接続をサポートします。
- HTTP/2
- HTTP/1.1
Note
- HTTP/2 は API IAP で終端され、Service へは HTTP/1.1 で転送されます
- gRPC のサポートはありません
Ingressリソースを使用したウェブ API の公開
-
公開するワークロードと Service リソースを用意します。ここでは例として、
example-svcService の 80 番ポートへアクセスすることでワークロードへアクセスできる状態になっているとします。 -
以下を参考に、Ingress マニフェストを作成します。
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: example-ingress spec: rules: - # Ingress に割り当てるドメインを指定します。 # 注意: ウェブアプリでの公開と異なり、`api.iap.pfcomputing.com` のサブドメインを指定します。 host: example.<組織名>.<クラスタ名>.api.iap.pfcomputing.com http: paths: - path: / pathType: Prefix backend: # 公開対象の Service 名とポートを指定します。 service: name: example-svc port: number: 80Warning
サブドメインの制限
ウェブ API 用 Ingress ではドメインとして
*.<組織名>.<クラスタ名>.api.iap.pfcomputing.comのみ使用できます。例えば、組織名が
fooでクラスタ名がsr1-01の場合は*.foo.sr1-01.api.iap.pfcomputing.comとなります。 -
以下を参考に、Ingress へアクセスするための Kubernetes ServiceAccount を作成します。
apiVersion: v1 kind: ServiceAccount metadata: name: example-sa # Ingress と同じ Namespace を指定します。 namespace: org-foo labels: # アクセスを許可する Ingress リソースの名前を指定します。 ingress.preferred.jp/allowed-ingress: example-ingressWarning
default ServiceAccount
Kubernetes が自動作成する
defaultという名前の ServiceAccount は Ingress へのアクセスに利用できません。 -
kubectl を利用して Kubernetes ServiceAccount のトークンを発行します。Ingress リソースに設定したドメインへ
https://をつけた値を Audience に設定する必要があります。トークンの有効期限は必要に応じて調整してください。$ kubectl create token example-sa --duration 12h --audience https://example.<組織名>.<クラスタ名>.api.iap.pfcomputing.com eyJ...Note
トークンの有効期限
無期限に有効なトークンを発行することはできません。代わりに十分に長い期間を指定してください。
-
発行したトークンを
AuthorizationHTTP ヘッダーに指定し、設定したドメインにアクセスします。公開したサービスにアクセスできることを確認します。$ curl --dump-header - -H "Authorization: Bearer eyJ..." https://example.<組織名>.<クラスタ名>.api.iap.pfcomputing.com
トークンの管理
発行済みの Kubernetes ServiceAccount のトークンを無効にするには、Kubernetes ServiceAccount 自体を削除してください。トークンごとに細かく無効化したい場合は Bound トークン の利用を検討してください。
Kubernetes ServiceAccount の ingress.preferred.jp/allowed-ingress ラベルを削除すると、トークンを無効化せずに一時的にアクセスを遮断できます。アクセスを再開する場合は再度ラベルを設定してください。
Ingress にアクセス可能な Kubernetes ServiceAccount の一覧は kubectl コマンドで確認できます。
$ kubectl get serviceaccount --selector ingress.preferred.jp/allowed-ingress
NAME SECRETS AGE
example-sa 0 4s
制限事項
- Service リソースの
NodePort、LoadBalancer、ExternalNameタイプを使用したサービスの公開をサポートしていません - 発行したトークンの Audience に一致するドメインが複数の Ingress リソースに設定されている場合は、認証エラーとしてステータスコード 401 が返されます
- 24 時間以上通信のない状態が続くとコネクションが切断されます
- リクエストボディのサイズ上限は 10MB です
ワークロードやジョブを外部イベント駆動で自動水平スケーリングする
PFCP では、KEDA (Kubernetes Event Driven Autoscaler) を利用した外部イベント駆動でワークロードやジョブを自動水平スケーリングする機能を提供しています。
利用可能な KEDA リソース
PFCP で利用できる主要な KEDA リソースは以下の 3 つです。
ScaledObject
ScaledObject は、スケーリング対象のワークロード(Deployment、StatefulSet など)と、そのスケーリングを制御するトリガーを定義するリソースです。
詳細については、ScaledObject の公式ドキュメントを参照してください。
ScaledJob
ScaledJob は、スケーリング対象のジョブと、そのスケーリングを制御するトリガーを定義するリソースです。
詳細については、ScaledJob の公式ドキュメントを参照してください。
TriggerAuthentication
TriggerAuthentication は、外部システムへの認証情報を管理するリソースです。
詳細については、TriggerAuthentication の公式ドキュメントを参照してください。
PFCP Prometheus メトリクスを利用したスケーリング
PFCP では、 Prometheus によるメトリクスモニタリング機能 を提供しています。ここでは、この機能を利用して Deployment の Pod レプリカ数を自動的にスケーリングする方法を説明します。
以下は、Prometheus メトリクスに基づいてアプリケーションのスケーリングを行うための KEDA の設定例です。ScaledObject リソースを作成し、myapp という名前の Deployment をスケーリング対象として指定しています。しきい値が 50 に対して、Prometheus のクエリは常に 100 を返すため、Pod のレプリカ数は 2 にスケーリングされます。
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: app-scaler
spec:
scaleTargetRef:
name: myapp # スケーリング対象の Deployment 名を指定
maxReplicaCount: 3 # 最大レプリカ数を指定
minReplicaCount: 0 # 最小レプリカ数を指定
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-k8s.monitoring-org-<org-name>.svc.cluster.local.:9090 # org-name: 組織名
query: "vector(100)" # 監視対象とするメトリクスを指定(ここでは常に 100 を返すクエリを指定)
threshold: "50" # スケーリングする条件を指定(ここではメトリクスが 50 を超えたとき)
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: stefanprodan/podinfo
name: podinfo
ports:
- containerPort: 9898
Prometheus で Pod のメトリクスを収集する方法については、メトリクスモニタリングとアラーティングを参照してください。
AWS Managed Prometheus メトリクスを利用したスケーリング
ここでは、外部リソースである AWS の Managed Prometheus(AMP)メトリクスを利用して Deployment の Pod レプリカ数を自動的にスケーリングする方法を例に説明します。
AWS IAM の設定
AMP メトリクスを利用するには、KEDA が AMP をクエリできる必要があります。以下の手順で設定してください。
- IAM で OpenID Connect(OIDC)ID プロバイダーをパブリッククラウドと ID 連携を構成するを参照して作成します。
- 利用している AMP ワークスペースの ARN を控えておきます。
AMPのセットアップ方法については、AWSのドキュメントを参照してください。
- KEDA が AMP のメトリクスをクエリするためのポリシーを作成します。Resource には利用している AMP ワークスペースの ARN を指定します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "aps:QueryMetrics" ], "Resource": [ "arn:aws:aps:<aws_region>:<aws_account_id>:workspace/<workspace_id>" ] } ] } - 先ほど作成したポリシーをアタッチする IAM ロールを作成し、KEDA のシステムコンポーネントに関連付けます。Principal には手順 1 で作成した OIDC プロバイダーを指定します。Condition に設定する KEDA Operator の Namespace は組織ごとに異なります。以下はその例です。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRoleWithWebIdentity", "Principal": { "Federated": "arn:aws:iam::<aws_account_id>:oidc-provider/token.<pfcp_cluster>.kubernetes.pfcomputing.com" }, "Condition": { "StringEquals": { "token.<pfcp_cluster>.kubernetes.pfcomputing.com:aud": [ "sts.amazonaws.com" ], "token.<pfcp_cluster>.kubernetes.pfcomputing.com:sub": [ "system:serviceaccount:keda-org-<pfcp_org_name>:keda-operator" ] } } } ] } - 作成したロールの ARN を控えておきます。この ARN は後で KEDA の設定で使用します。
KEDA リソースの作成
以下は、AMP メトリクスに基づいてアプリケーションのスケーリングを行うための KEDA の設定例です。
TriggerAuthentication の.spec.podIdentity.roleArnに先ほど控えた IAM ロールの ARN を指定すると、KEDA はそのロールを使用して AMP のメトリクスをクエリします。
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: amp-query-role
spec:
podIdentity:
provider: aws
roleArn: <roleArn> # 先ほど控えた IAM ロールの ARN を指定
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: app-scaler
spec:
scaleTargetRef:
name: myapp
maxReplicaCount: 10
minReplicaCount: 0
triggers:
- type: prometheus
authenticationRef:
name: amp-query-role
metadata:
awsRegion: <aws_region> # AMP のリージョンを指定する
serverAddress: https://aps-workspaces.<aws_region>.amazonaws.com/workspaces/<workspace_id> # AMP のエンドポイントを指定する
query: "sum(rate(http_requests_total[1m]))" # 監視対象とするメトリクスを指定(ここでは 1 分間の HTTP リクエスト数)
threshold: "50" # スケーリングする条件を指定(ここではリクエスト数が 50 を超えたとき)
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: stefanprodan/podinfo
name: podinfo
ports:
- containerPort: 9898
機密データ(Secret)を扱う
Kubernetes は標準機能として、Secrets を提供しています。
Secret は機密データを管理するためのリソースですが、API やマニフェストでは base64 エンコードされたデータとして扱われます。このデータは暗号化されておらず、簡単に平文に戻せるという問題があります。一般的に、Kubernetes リソースのマニフェストはGitOpsやInfrastructure as Code (IaC) 手法を使用し、YAML 形式で git リポジトリに管理します。しかし、Secret のデータは簡単に平文に戻せるため、そのまま git リポジトリに保存することは不適切です。
PFCP では、機密データを通常の Kubernetes マニフェストと一緒に GitOps 方式で管理できるように、機密データを暗号化する SealedSecret を提供します。
概要
SealedSecretは暗号化された機密データが含まれるリソースです。gitリポジトリに保存できます。
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: mysecret
namespace: mynamespace
spec:
encryptedData:
foo: AgBy3i4OJSWK+PiTySYZZA9rO43cGDEq..... # 暗号化された機密データ
このSealedSecretリソースはクラスタに適用された際、クラスタ内の鍵で復号され、通常のSecretリソースに展開されます。
apiVersion: v1
kind: Secret
metadata:
name: mysecret
namespace: mynamespace
data:
foo: YmFy # base64でエンコードされた"bar"
SealedSecretを作成する
SealedSecret を作成するには、kubeseal コマンドを利用します。kubeseal をインストールするには幾つかの方法があります。詳しくは sealed-secrets のドキュメントをご参照ください。Bitnami がメンテナンスするリリースを利用することを推奨します。
まずは、通常の Kubernetes Secret を作成し、ファイルに保存します。kubectl コマンドで作成できます。
echo -n secret-data | kubectl create secret generic mysecret \
--dry-run=client \
--from-file=secret-name=/dev/stdin \
-o yaml >secret.yaml
このようなファイルができます。
apiVersion: v1
kind: Secret
metadata:
name: mysecret
data:
secret-name: c2VjcmV0LWRhdGE=
次に、kubeseal コマンドで、SealedSecret を作成します。kubeseal はクラスタ内の sealed-secrets コントローラから公開鍵(証明書)を取得し、取得した公開鍵でSecretを暗号化し、SealedSecretを出力します。
kubeseal \
--controller-namespace sealed-secrets-org-<組織名> \
-f secret.yaml \
-o yaml > sealedsecret.yaml
このようなファイルができます。
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: mysecret
spec:
encryptedData:
secret-name: "AgBy3i4OJSWK+PiTySYZZA9rO43cGDEq....."
この sealedsecret.yamlファイルをgitリポジトリに保存できます。
Note
secret.yamlには暗号化されていない機密データが含まれるため、決してgitリポジトリに保存しないでください。
git add sealedsecret.yaml
git commit -m "add new secret"
SealedSecretをクラスタに適用するとクラスタ側で自動的に展開され、通常の Kubernetes Secret と同様に利用できます。詳しくは Kubernetes ドキュメントをご参照ください。
公開鍵、秘密鍵の扱い
機密データを暗号化、復号するためのキーペア(公開鍵、秘密鍵)は組織専用で、原則 PFCP で管理します。ユーザ側で管理する必要はありません。公開鍵と秘密鍵は自動的に、定期的にローテーションされます。秘密鍵はクラスタ内にしか存在しないので、ご安心ください。
パブリッククラウドと ID 連携を構成する
パブリッククラウドのリソースへのアクセスに使う鍵は強力な認証情報であり、外部への持ち出しはセキュリティリスクがあります。 鍵を持ち出さずにパブリッククラウドのリソースを利用するために、PFCP ではパブリッククラウドとの ID 連携をサポートします。 ID 連携を使用すると、Kubernetes クラスタの ServiceAccount に対してパブリッククラウドの権限が付与され、アクセスが可能になります。
ここでは、Amazon Web Service(以下、AWS)と Google Cloud の 2 種類のパブリッククラウドについて、ID 連携を組む方法について紹介します。
AWSとの連携
AWS 側の設定
-
AWS ドキュメント IAM で OpenID Connect (OIDC) ID プロバイダーを作成する - AWS Identity and Access Management を参照して、アクセスしたい AWS アカウント内に OIDC プロバイダを作成します。1
- プロバイダ(発行者)URL は 拠点と計算ノード を参照してください。
- 許可するオーディエンス:
sts.amazonaws.com
-
AWS へのアクセスに使用する IAM ロールを作成します。この IAM ロールは、ID 連携により Kubernetes ServiceAccount に紐づけて使用します。
-
ID 連携による紐づけを許可するために、IAM ロールを引き受けさせる Kubernetes ServiceAccount を指定して、以下のような信頼ポリシを構成します(ドキュメント)。
{ "Version": "2012-10-17", "Statement": [{ "Sid": "", "Effect": "Allow", "Principal": { // 前のステップで作成した oidc provider の ARNを指定します。 "Federated": "arn:aws:iam::XXXXXXXXXXX:oidc-provider/token.<pfcp_cluster>.kubernetes.pfcomputing.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { // このIAMロールを引き受けさせる Kubernetes ServiceAccount 名を指定します。 "token.<pfcp_cluster>.kubernetes.pfcomputing.com:sub": "system:serviceaccount:<namespace>:<serviceaccount>" } } }] }Warning
Conditionの設定を必ず記述してください。忘れると、他の組織を含むすべての ServiceAccount に対して権限が付与されてしまいます。
-
AWS では、Cloud Trail による ID 連携の監査ログがデフォルトで有効になっており、90 日間保存されます。90 日を超えて監査ログを保存しておきたい場合は、AWS アカウント の証跡の作成 - AWS CloudTrail を参照し設定を変更します。
Kubernetesクラスタ側の設定
-
ServiceAccount の annotations に、ServiceAccount に付与する AWS IAM ロールを指定します。
apiVersion: v1 kind: ServiceAccount metadata: name: foo annotations: aws.id-federation.preferred.jp/role-arn: "arn:aws:iam::{aws_account_id}:role/{role}" -
Pod を作成する際に、
.spec.serviceAccountNameにこの ServiceAccount を指定します。 Pod 内で AWS SDK を使用すると、ServiceAccount に紐づいた AWS IAM Role を用いて AWS にアクセスします。 セッショントークンの有効期限は 1 時間です。AWS SDK を使い続ける限り自動で更新されます。 -
動作確認をします。まず、Pod が使用している IAM ロールを確認します。
$ kubectl get po <pod> -o yaml | grep AWS_ROLE_ARN: AWS_ROLE_ARN: arn:aws:iam::861856390547:role/id-federation-test-sr1-01次に、Pod に Web ID token ファイルのマウントがあることを確認します。
$ kubectl get po <pod> -o yaml | grep AWS_WEB_IDENTITY_TOKEN_FILE: AWS_WEB_IDENTITY_TOKEN_FILE: /var/run/secrets/sts.amazonaws.com/serviceaccount/token
Google Cloud との連携
PFCP には gcp-workload-identity-federation-webhook がデプロイされており、これを使い Google Cloud との ID 連携を構成できます。
Google Cloud 側の設定
Kubernetes との Workload Identity 連携を構成する | IAM のドキュメント | Google Cloud を参照し、以下の設定をおこないます。
-
アクセスしたい Google Cloud プロジェクト内に Workload Identity のプールとプロバイダを作成します。
-
Google Cloud へのアクセスに使用する Google IAM サービスアカウントを作成し、許可するリソースに対するアクセス権を付与します。このサービスアカウントは、ID 連携により Kubernetes ServiceAccount に紐づけて使用します。
-
ID 連携による紐づけを許可するために、Workload Identity ユーザロール(
roles/iam.workloadIdentityUser)を上記の Google IAM サービスアカウントに付与します。このとき、Kubernetes ServiceAccount に限定して権限の借用を許可するために、以下をメンバーとして指定します。principal://iam.googleapis.com/projects/<Google CloudのプロジェクトID> \ /locations/global/workloadIdentityPools/<作成したWorkload IdentityプールのID> \ /subject/<クラスタの発行元URL>::system:serviceaccount:<Kubernetes ServiceAccountのNamespace>:<Kubernetes ServiceAccountのName>
Kubernetes クラスタ側の設定
-
ServiceAccount の annotations に、Workload Identity プロバイダ、借用させる IAM サービスアカウント、Workload Identity プロバイダが期待するオーディエンスの値をアノテーションとして設定します。
apiVersion: v1 kind: ServiceAccount metadata: annotations: googlecloud.id-federation.preferred.jp/workload-identity-provider: |- projects/<Google CloudのプロジェクトID>/locations/global/workloadIdentityPools/<作成したWorkload IdentityプールのID>/providers/<作成したWorkload IdentityプールプロバイダのID> googlecloud.id-federation.preferred.jp/service-account-email: |- <Google IAM サービスアカウント名>@<Google Cloudのプロジェクト名>.iam.gserviceaccount.com googlecloud.id-federation.preferred.jp/audience: <Workload Identity プロバイダが期待するオーディエンス> -
Pod を作成する際に、
.spec.serviceAccountNameにこの ServiceAccount を指定します。 Pod 内で Google Cloud SDK を使うと、指定した ServiceAccount に紐づいた Google IAM サービスアカウントを借用して Google Cloud にアクセスします。 認証情報の有効期限はデフォルトで 24 時間です。Google Cloud SDK を使い続ける限り、自動で更新されます。
より詳細については gcp-workload-identity-federation-webhook の README をご覧ください。
GitHub Actions ジョブを実行する
PFCP では、クラスタ上で GitHub Actions ジョブを実行できます。 クラスタ上のリソースを活用した CI/CD パイプラインの構築が可能です。
GitHub Actions ジョブを実行する手段として、PFCP では Actions Runner Controller (ARC) を提供しています。 ARC を利用することで、GitHub Actions ジョブを実行するためのセルフホスト型ランナーをクラスタ上にデプロイできます。
以下では、ARC を利用した GitHub Actions ジョブの実行方法を紹介します。
セルフホスト型ランナーの構成
まず、以下の手順にしたがい、クラスタ上にセルフホスト型ランナーを構成します。 ランナーの個数は、キューに積まれたジョブの数におうじて自動でスケーリングします。
-
GitHub App を作成し、対象リポジトリにインストールします。また、GitHub App の認証情報を格納した Kubernetes Secret を作成します。
- 詳細は GitHub API に対する ARC の認証 - GitHub ドキュメント を参照してください。
-
クラスタに
AutoscalingRunnerSetリソースを作成します。例を以下に示します。apiVersion: actions.github.com/v1alpha1 kind: AutoscalingRunnerSet metadata: name: NAME spec: githubConfigUrl: https://github.com/ORG/REPO # ランナーを登録するリポジトリ githubConfigSecret: SECRET_NAME # 1 で作った Secret の名前 runnerScaleSetName: RUNNER_NAME # GitHub Actions ジョブの "runs-on" で指定することになる名前 # Runner の自動スケーリング設定 minRunners: 0 maxRunners: 20 # Runner pod のテンプレート template: spec: containers: - name: runner image: ghcr.io/actions/actions-runner command: - /home/runner/run.sh # リソース量は実行したいジョブに合わせて調整してください resources: requests: cpu: 100m limits: memory: 256MiNote
AutoscalingRunnerSet リソースの
app.kubernetes.io/versionラベルと.spec.listenerTemplateフィールドは自動で設定されます。 存在する場合は上書きされます。
GitHub Actions ジョブでの利用
作成したセルフホスト型ランナーを GitHub Actions ジョブで利用するには、以下の手順を実行します。
- ジョブの
runs-onプロパティに、AutoscalingRunnerSet のrunnerScaleSetNameに設定した名前を指定します。jobs: build: runs-on: RUNNER_NAME steps: - ...
参考
Actions Runner Controller について詳しくは、公式ドキュメントを参照してください。
- Actions Runner Controller - GitHub Docs
- Deploying runner scale sets with Actions Runner Controller - GitHub Docs
リレーショナルデータベースを実行する
PFCP では、 MySQL を簡単にデプロイして利用できるようにするための MOCO を提供しています。
Note
MOCO が作成する MySQL などのワークロードは、組織の他のワークロードと同様に計算ノード上にデプロイされます。
利用可能な MOCO リソース
PFCP で利用できる MOCO リソースは以下の 2 つです。
MySQLCluster
MySQLCluster は、 MySQL クラスタを定義するリソースです。このリソースを作成することで、 MOCO により管理された MySQL クラスタがデプロイされます。
詳細については、MOCO の公式ドキュメント Creating clustersを参照してください。
BackupPolicy
BackupPolicy は、 MySQL のバックアップを管理するリソースです。このリソースを作成することで、 MySQL クラスタの定期的なバックアップを構成できます。
MOCO では bucketConfig によってバックアップ先を指定します。 backendType には s3 、 gcs 、 azure を指定できます。 PFCP で利用する場合は、クラスタからアクセスできるオブジェクトストレージと、そのオブジェクトストレージにアクセスするための認証設定をあらかじめ用意してください。
詳細については、MOCO の公式ドキュメント Backup and restoreを参照してください。
MySQL インスタンスの起動
以下に、 MySQL インスタンスをデプロイするための MySQLCluster リソースの例を示します。
storageClassName には、ブロックストレージの StorageClass 名 standard-rwo-<組織名> を指定してください。 MySQL のデータディレクトリは単一の Pod から書き込むため、通常は RWX のファイルストレージではなく ReadWriteOncePod を利用できるブロックストレージを利用します。
apiVersion: moco.cybozu.com/v1beta2
kind: MySQLCluster
metadata:
name: moco-test-instance
spec:
replicas: 1 # Change replicas to configure replication
podTemplate:
spec:
containers:
- name: mysqld
image: ghcr.io/cybozu-go/moco/mysql:8.4.8
resources:
limits:
cpu: "2"
memory: "8Gi"
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes:
- ReadWriteOncePod
storageClassName: standard-rwo-<組織名>
resources:
requests:
storage: 4Gi
バックアップを構成する
BackupPolicy を参照する MySQLCluster には、バックアップ用の CronJob moco-backup-<MySQLCluster 名> が作成されます。
バックアップジョブは spec.jobConfig.serviceAccountName で指定した ServiceAccount として実行されます。
オブジェクトストレージへアクセスするための認証情報は、 ServiceAccount または env / envFrom で渡します。
PFCP でパブリッククラウドとの ID 連携を利用する場合は、パブリッククラウドと ID 連携を構成する も参照してください。
workVolume は、ダンプファイルや圧縮済みデータを一時的に配置するための作業領域です。バックアップ本体の保存先ではありません。
emptyDir や ephemeral のように Pod local storage を使う構成では、バックアップ時に必要な一時領域を十分に確保できないことがあります。
そのため、バックアップ対象が大きい場合は、 MySQL データ用の PVC とは別に作業用の PVC を用意して workVolume から参照する構成を推奨します。
以下に、 Google Cloud Storage に日次バックアップを保存する BackupPolicy の例を示します。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: moco-backup-work
spec:
accessModes:
- ReadWriteOncePod
storageClassName: standard-rwo-<組織名>
resources:
requests:
storage: 20Gi
---
apiVersion: moco.cybozu.com/v1beta2
kind: BackupPolicy
metadata:
name: daily-backup
spec:
schedule: "@daily"
jobConfig:
serviceAccountName: db-backup-sa
bucketConfig:
bucketName: example-moco-backup
endpointURL: https://storage.googleapis.com
backendType: gcs
workVolume:
persistentVolumeClaim:
claimName: moco-backup-work
moco-backup-work はバックアップ Job の一時作業領域用 PVC です。 MySQL のデータ領域とは分けて用意します。
MySQLCluster 側では spec.backupPolicyName に BackupPolicy 名を指定します。 MOCO は古いバックアップを自動削除しないため、バックアップ先のバケットでは必要に応じてライフサイクル設定も構成してください。
MySQL インスタンスに接続する
MOCO は各 MySQLCluster に対して、書き込み用の moco-<MySQLCluster 名>-primary Service と読み取り用の moco-<MySQLCluster 名>-replica Service を作成します。
たとえば Namespace org-<組織名> に moco-test-instance を作成した場合を考えます。
この場合は moco-moco-test-instance-primary.org-<組織名>.svc と moco-moco-test-instance-replica.org-<組織名>.svc が利用できます。
また、 MOCO は moco-readonly 、 moco-writable 、 moco-admin という代表的な MySQL ユーザを用意します。認証情報の取得や対話的な接続には、 kubectl-moco kubectl plugin が便利です。
$ kubectl moco -n org-<組織名> credential -u moco-admin moco-test-instance --format mycnf
$ kubectl moco -n org-<組織名> mysql -it moco-test-instance
$ kubectl moco -n org-<組織名> mysql -u moco-writable moco-test-instance -- -e "CREATE DATABASE app"
アプリケーション Pod から接続する場合は、書き込み用途では moco-<MySQLCluster 名>-primary を、読み取り用途では moco-<MySQLCluster 名>-replica を接続先として利用してください。詳しくは、 MOCO の公式ドキュメント Using the Cluster を参照してください。
Note
MySQL を運用する際のプラクティス
- MySQL は MOCO がサポートするバージョンを利用してください。 MOCO の機能を利用して MySQL のアップグレードを行うことができます。
- 可用性を高めたい場合は
replicasを2以上にしてレプリケーションを行ってください。- 永続性が必要な場合は
BackupPolicyを利用してバックアップを作成してください。
メトリクスモニタリングとアラーティング
PFCP では、Grafana1・Prometheus2 を使用したメトリクスモニタリング機能とアラート機能をマネージドサービスとして提供しています。また、Prometheus Operator を導入しており、Kubernetes カスタムリソースを用いてモニタリング対象やアラートルールを宣言的に管理できます。
モニタリング機能へのアクセス
ポータルのトップページ に掲載のリンクからモニタリングサービスの各機能にアクセスできます。
Grafana ダッシュボード
Kubernetes ワークロードの状況を可視化する Grafana ダッシュボードを標準提供しています。 標準提供のダッシュボードには、例えば以下のダッシュボードが含まれます。
- kube-prometheus > Kubernetes / Compute Resources / Namespace (Workloads)
- Namespace 単位のリソース使用状況
- kube-prometheus > Kubernetes / Compute Resources / Pod
- Pod のリソース使用状況
また、Grafana WebUI より任意のダッシュボードを作成できます。 ダッシュボードを追加する場合は専用のフォルダを作成し、その中にダッシュボードを作成することを推奨します。
メトリクスモニタリング
Pod のメトリクスをスクレイプする
Prometheus Operator の ServiceMonitor、PodMonitor カスタムリソースを使用して、Pod のメトリクスをスクレイプできます。また取得したメトリクスを可視化するには Grafana ダッシュボードが使用できます。
ServiceMonitor、PodMonitor の使い方については、Prometheus Operatorの公式ドキュメントをご参照ください。
アラートルールを追加する
Kubernetes ワークロードの健全性を確認するアラートルールを標準で提供しています。標準で提供されるアラートルールは Prometheus WebUI の Alerts タブで確認できます。
加えて、Prometheus Operator の PrometheusRule カスタムリソースを使用して任意のアラートルールを追加できます。 PrometheusRule の使い方については、以下をご確認ください。
アラート通知先を追加する
Prometheus Operator の AlertmanagerConfig カスタムリソースを使用して、アラートを任意のサービスやツールに送信できます。 AlertmanagerConfig の使い方については、以下をご確認ください。
サンプルのマニフェストファイル
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: alertmanager-config
spec:
inhibitRules:
- equal:
- namespace
- alertname
sourceMatch:
- name: severity
value: critical
targetMatch:
- matchType: =~
name: severity
value: warning|info
- equal:
- namespace
- alertname
sourceMatch:
- name: severity
value: warning
targetMatch:
- name: severity
value: info
- equal:
- namespace
sourceMatch:
- name: alertname
value: InfoInhibitor
targetMatch:
- name: severity
value: info
route:
groupBy:
- alertname
groupInterval: 5m
groupWait: 30s
receiver: slack
repeatInterval: 12h
routes:
- matchers:
- name: alertname
value: InfoInhibitor
receiver: "null"
- matchers:
- name: alertname
value: Watchdog
receiver: "null"
receivers:
- name: "null"
- name: slack
slackConfigs:
- apiURL:
name: alertmanager-cred
key: slack-url
sendResolved: true
Prometheus サーバの仕様
提供する Prometheus サーバの仕様は次のとおりです。
- メトリクス保持期間(Retention time): 15 日
- メトリクス保持サイズ(Retention size): 95GiB
Warning
メトリクス保持期間、保持サイズの変更はサポートしていません。
制限事項
- Grafana・Prometheus において、組織内の権限管理機能を提供していません。一般ユーザが全てのメトリックやダッシュボードが閲覧可能です。
- セキュリティ上の理由により ServiceMonitor カスタムリソースでは
spec.endpoints[].bearerTokenFileフィールドを使用できません。代わりにspec.endpoints[].authorizationフィールドでトークンを指定できます。
-
Grafana はさまざまなデータソースからの時系列データを可視化するためのオープンソースのダッシュボードツールです。https://grafana.com/docs/grafana/latest ↩
-
Prometheus は、時系列データの収集とクエリに特化したオープンソースの監視・アラートシステムです。 https://prometheus.io/docs/ ↩
Kubernetes リソースをダッシュボードで確認する
PFCP では、Kubernetes クラスタの Web UI として Headlamp を提供しています。 Headlamp では、ユーザの権限でアクセス可能な Kubernetes リソースをブラウザから確認できます。 また、リソースによっては作成・更新・削除などの操作も行えます。
アクセス方法
- PFCP ポータル にログインします。
- トップページで対象クラスタを選択し、Headlamp リンクをクリックします。
Note
Headlamp の URL は、
https://<組織名>.<クラスタ名>.headlamp.pfcomputing.comの形式です。 通常はポータルのリンクからアクセスします。
主な使い方
Headlamp では、次のような情報を確認できます。
- Pod、Deployment、Job、Service などのリソースの状態
- 組織に割り当てられた ReservedNode の情報
- リソース詳細画面でのイベント・マニフェストの詳細
また、Pod の詳細画面では Prometheus のメトリクス表示機能を利用できます。
制限事項
- 表示・操作できるリソースは、ユーザへ付与された Kubernetes 権限に依存します。
Pod にセキュリティポリシを適用する
Kubernetes では、セキュリティリスクを低減するために Pod Security Standards(以下、PSS)という Pod セキュリティの推奨構成が定義されています。PFCP では、PSS に準拠した Pod セキュリティプロファイルが適用されます。
PSS には、Restricted・Baseline・Privileged の 3 つのポリシーがあり、PFCP ではデフォルトで Baseline が適用されます。Baseline は、コンテナワークロードに対する制限を少なめにしつつも、既知の特権昇格に対し対策されたポリシーです。
より Pod セキュリティを強化したい場合には、Restricted ポリシーも利用できます。
Pod の label に policy.preferred.jp/pod-security: restricted をつけることで Restricted が適用され、ポリシーに違反する Pod は作成できなくなります。
Note
特権昇格が可能な Privileged ポリシーは利用できません。
PSS の各ポリシーの詳細については、 Kubernetesの公式ドキュメント をご参照ください。
MN-Core シリーズ利用時のプロファイル
MN-Core シリーズのリソースを要求する Pod を作成すると、MN-Core シリーズを用いた演算の処理速度を向上するために、自動的に SYS_NICE capability が付与されます1。 この対応は、MN-Core シリーズのリソースを要求する Pod に限定されます。 MN-Core シリーズのリソースを要求しない Pod の場合は、PSS Baseline に準拠しているため、SYS_NICE capability は付与できません。
-
Kubernetes の標準機能ではなく、PFCP 独自の拡張です。 ↩
仕様: 拠点と計算ノード
拠点
SR1
- インターネット向け通信のソース IP アドレス:
202.214.130.143/32
クラスタ
- SR1-01
- ID 連携用プロバイダ(発行者)URL:
https://token.sr1-01.kubernetes.pfcomputing.com
- ID 連携用プロバイダ(発行者)URL:
IK1
- インターネット向け通信のソース IP アドレス:
153.120.101.128/28- 予告なく変更される場合があります
クラスタ
- IK1-01
- ID 連携用プロバイダ(発行者)URL:
https://token.ik1-01.kubernetes.pfcomputing.com
- ID 連携用プロバイダ(発行者)URL:
計算ノード
MN-Server 2 V1(ノード名: isXXzXcqXX)
| 項目 | 仕様 |
|---|---|
| CPU | Intel Xeon Platinum 8480+ Processor x 21 |
| メモリ | DDR5-4800 64 GB x 16 (合計 1 TB) |
| アクセラレータ | MN-Core 2 ボード(16 GB)x 8 |
| データドライブ | 15.3 TB NVMe U.3 PCIe Gen4 SSD x 3 |
| NIC(オンボード) | 10 GbE x 2 |
| NIC(データ) | NVIDIA ConnectX-6 Dx EN adapter card、 100GbE、 Dual-port QSFP56 x 2 2 |
より詳しくは、MN-Core 2 Hardware Catalog の MN-Server 2 V1 をご覧ください。
仕様: ソフトウェアバージョン
クラスタとアドオン
| ソフトウェア名 | バージョン | ドキュメントサイト |
|---|---|---|
| Kubernetes | v1.35.3 | https://kubernetes.io/ |
| Cilium | v1.18.9 | https://docs.cilium.io/ |
| Prometheus Operator | v0.90.1 | https://prometheus-operator.dev/ |
| Hierarchical Namespaces | v1.1.0-pfnet.11 | https://github.com/pfnet/hierarchical-namespaces |
| Amazon EKS Pod Identity Webhook | v0.6.14 | https://github.com/aws/amazon-eks-pod-identity-webhook |
| GCP Workload Identity Federation Webhook | v0.6.0 | https://github.com/pfnet-research/gcp-workload-identity-federation-webhook |
| Image pull secrets provisioner | v0.1.2 | https://github.com/pfnet/image-pull-secrets-provisioner |
| Astra Trident | v26.02.1 | https://docs.netapp.com/us-en/trident/index.html |
| Flux | v2.8.5 | https://fluxcd.io/flux |
| KEDA | v2.19.0 | https://keda.sh |
| Actions Runner Controller | v0.14.1 | https://github.com/actions/actions-runner-controller |
| Sealed Secrets | v0.36.6 | https://github.com/bitnami-labs/sealed-secrets |
| Headlamp | v0.41.0 | https://headlamp.dev/ |
| MOCO | v0.32.0 | https://cybozu-go.github.io/moco/ |
モニタリングサービス
| ソフトウェア名 | バージョン | ドキュメントサイト |
|---|---|---|
| Grafana | v12.3.1 | https://grafana.com/docs/grafana/latest/ |
| Prometheus | v3.10.0 | https://prometheus.io/ |
| Alertmanager | v0.31.1 | https://prometheus.io/docs/alerting/latest/alertmanager/ |